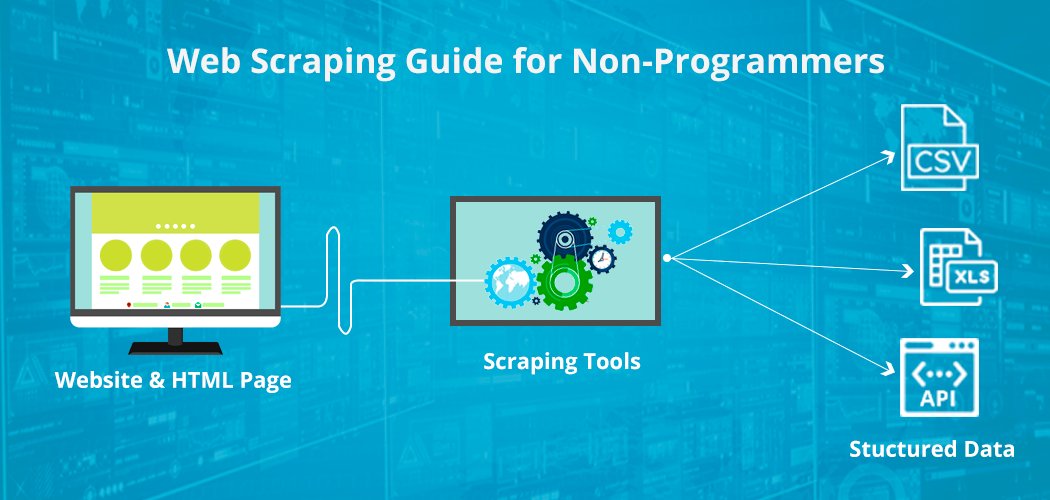
Do you ever wonder how web scraping can unlock the business potential for you?
Of course, you do!
But then you immediately think of the hurdles of web scraping – you can get blocked, how it’s difficult to get JS/AJAX data, how it’s challenging to scale it up even if you can start, how maintaining it is a pain in the neck and even if you get going, structure changes in the website can completely derail your efforts. This is what stops you from pursuing it, right?
No worries!
We have put together the Beginners Guide to web scraping. With some or none of the technical expertise as a beginner, you can get going using this guide. It will enable you to explore web scraping and help you gain competitive advantage over others.
What is Web Scraping?

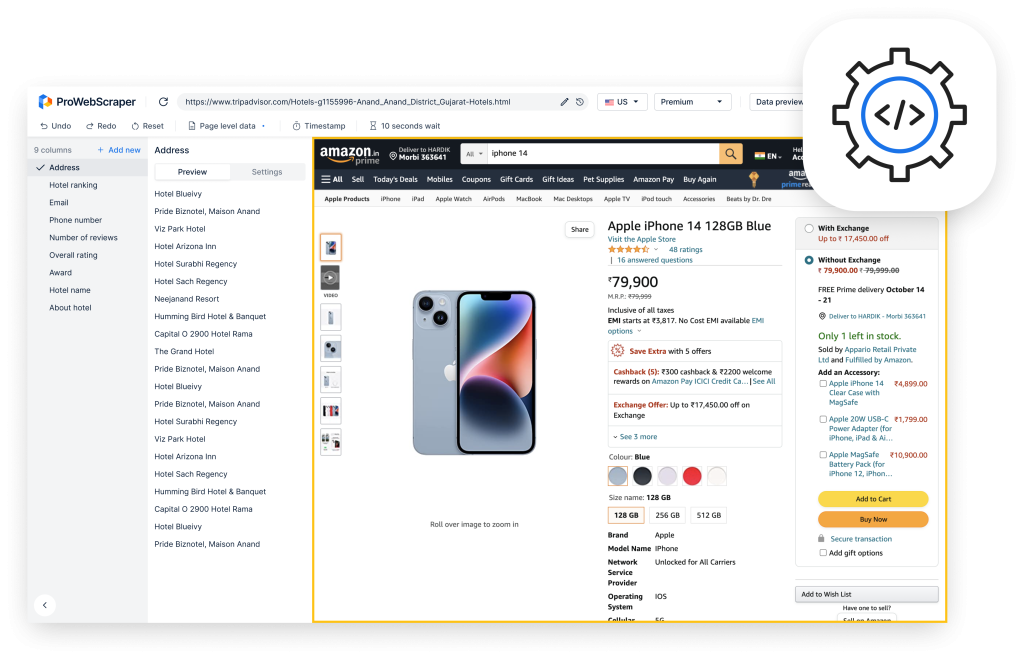
Web scraping is an automated way of extracting large chunks of data from websites which can then be saved on a file in your computer or accessed on a spreadsheet.
When you access a web page, you can only view the data but cannot download it. Yes, you can manually copy and paste some of it but it is time-consuming and not scalable. Web scraping automates this process and quickly extracts accurate and reliable data from web pages that you can use for business intelligence.
You can scrape vast quantities of data and of different kinds of data as well. It could be text, images, email ids, phone numbers, videos etc. For your specific projects, you may need domain specific data such as financial data, real estate data, reviews, price or competitor data. You can extract the same using web scraping tools. At the end of the process, you will get it all in a format of your choice such as text, JSON or CSV which you can harness the way you want.

- Scalable: Handle large-scale scraping needs with ease.
- Robust QA: Hybrid QA process for accurate data extraction.
- Uninterrupted Scraping: residential proxies that never get blocked while scraping.
How does Web Scraping Work?
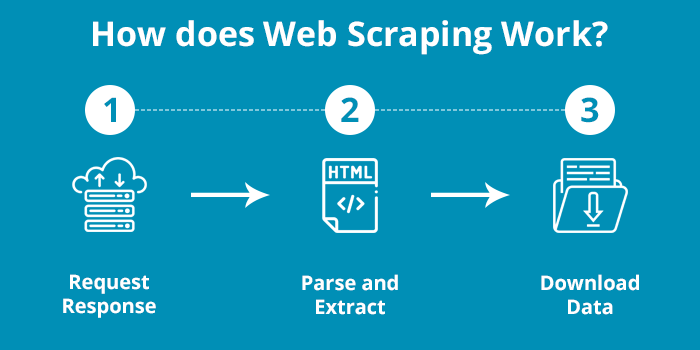
Seeing is believing, right?
So let me show you how web scraping actually works.
While there are many different ways, I will show the simplest and the easiest possible way of web scraping.
Here’s how it works.
1. Request-Response
The first simple step in any web scraping program (also called a “scraper”) is to request the target website for the contents of a specific URL.
In return, the scraper gets the requested information in HTML format. Remember, HTML is the file type used to display all the textual information on a webpage.
2. Parse and Extract
In simple terms, HTML is a markup language with a simple structure.
When it comes to Parsing, it usually applies to any computer language. It is the process of taking the code as text and producing a structure in memory that the computer can understand and work with.
To put it simply, HTML parsing is basically taking in HTML code and extracting relevant information like the title of the page, paragraphs in the page, headings in the page, links, bold text etc.
All you need is regular expressions wherein a group of regular expressions defines a regular language and a regular expression engine automatically generating a parser for that language, allowing pattern matching and extraction of text.
3. Download Data
The final part is where you download and save the data in a CSV, JSON or in a database so that it can be retrieved and used manually or employed in any other program.
With this, you can extract specific data from the web and store it typically into a central local database or spreadsheet for later retrieval or analysis.
That’s it. This is how a web scraper works!
Advanced Techniques for Web Scraping
Web Scraping Using Machine Learning
- Machine learning and computer vision are now being harnessed to identify and scrape information from web pages by interpreting pages visually as a human being would.
- How it works is quite straightforward. A machine learning system will usually assign each of its classifications a confidence score which is a measure of the statistical likelihood that the classification is correct, considering the patterns discerned in the training data.
- With the researchers’ new system, if the confidence score is too low, the system automatically generates a web search query designed to pull up texts likely to contain the data it’s trying to extract.
- Next, it tries to scrape the relevant data from one of the new texts and reconciles the results with those of its initial extraction. If the confidence score remains quite low, it moves on to the next text pulled up by the search string and so on.
What is web scraping used for?
Web scraping has countless applications and uses. It can be used in every known domain. But it would suffice to point out how it is used in a few areas.
1. Price Monitoring
In e-commerce business, companies use competitive pricing as a strategy. In order to succeed in such a business, you need to keep track of pricing strategy of the competitors. According to the data of pricing, you can decide your own pricing. You would be surprised how web scraping can help you get an edge over others when it comes to price monitoring.
- Price is the decisive factor in businesses like e-commerce. E-commerce companies would like to keep track of prices of their competitors and pitch their prices accordingly to get a strategic advantage.
- Moreover, it is not a one-time affair. Prices keep changing and e-commerce companies need the real-time updates on price changes happening on their competitors’ websites.
- This is where web scraping can give you a great edge. With the help of web scraping, you can scrape the prices on an ongoing basis and keep track of your competitors’ pricing strategies.
2. Lead Generation
For any business, marketing is of paramount significance. For marketing, you need to have contact details of those to whom you send your marketing material. This is what lead generation is all about. With the help of web scraping, you can get incredibly large number of data from which you can generate countless leads. Here’s how it works:
- When you think of accelerating your marketing campaign, what’s the first thing you need? Leads, of course!
- You need them in bulk- thousands and thousands of email ids, phone numbers etc. No way to get it manually from websites spread all across the Internet.
- Web scraping can extract these email ids and phone numbers with surgical precision. It is not merely accurate but also lightening quick. You get it in a fraction of the time you would take to do it manually.
- You also get it in a CSV or a format that you can readily employ for further processing. You can also integrate it in yours sales or automation tools.
3. Competitive Analysis
In an age of cut-throat competitive, you need to know your competitors very well and understand their strategies, strengths and weakness. In order to do this, you need lots and lots of data. This is where web scraping can help. Here’s how it works:
- You would definitely need to do some competitive analysis from time to time. But the data you need is scattered here, there and everywhere. How do you access it?
- This is where web scraping can create an advantage for you. You can quickly scrape the data you need from multiple sources and leverage it for competitive analysis.
- The faster and more efficient web scraping tools you have, the better competitive analysis would be. It’s that simple!
4.Fetching Images and Product Description
Every new e-commerce business needs product descriptions and images of thousands of products that need to be displayed on the website. How does one write product descriptions and create new images for the large number of products overnight? Web scraping can bail you out here too:
- Let’s say you come up with an e-commerce business. You will need images and product descriptions of hundreds of thousands of products, won’t you?
- You can, of course, get somebody to copy and paste it manually from some other e-commerce site. It will probably take forever to do it. Instead, web scraping can automate the process of extracting the images and product description and can complete the task in no time!
- So if you want to run an e-commerce business, web scraping is sort of integral to it, don’t you think?
- Is web scraping legal?
Is web scraping legal?
When you scrape data from a website, it may be copyrighted data or protected by some or the other law. What would happen if you scrape such data? Will it be legal if you scrape it or will it land you in trouble?
When you scrape data from a website, it may be copyrighted data or protected by some or the other law. What would happen if you scrape such data? Will it be legal if you scrape it or will it land you in trouble?
Well, it’s one of those tricky issues where nobody seems to be certain or clear.
As a beginner, you may also be scared about doing web scraping as you may not be clear whether it’s legal or not.
No worries. At the end of this section, you will be absolutely clear regarding legality of web scraping. Here’re a few important points you need to consider regarding its legality.
- Scrape public data as much you want. It would keep you safe. If you trespass and encroach upon private data, you would be inviting trouble.
- If you do it in an abusive manner, you would be in violation of CFAA. Using this data for commercial purposes would constitute further violation of the same.
- Likewise, if you scrape and use copyrighted data for commercial purposes, it would be unethical and illegal.
- If you respect and follow Robots.txt, you would generally be safe. If you violate its terms, you are opening yourself up for legal action.
- The same applies to Terms of Service (ToS). As long as you don’t violate its terms, you will be safe.
- If you use API, in case it is provided, it would be perfectly legal vis-à-vis scraping.
- Follow a reasonable crawl rate like 1 request per 10-15 seconds and you will be fine.
- Aggressive and relentless scraping can land you in trouble. If you hit the servers too frequently, you may cause damage to the site. You could be in for trouble for this. So avoid hitting servers too frequently and you will be fine.
Challenges in Web Scraping

While web scraping is easy in some ways, it’s quite challenging in certain aspects. Here’re the major web scraping challenges that you will come across:
- Frequent Structure Changes
- HoneyPot Traps
- Anti-scraping Mechanisms
- Data Quality
Let’s learn about each one in detail:
1. Frequent Structure Changes
Once you set up your scraper, you may think that it’s all set. But you may be in for a surprise here. Structure changes can pose quite a challenge for your web scraping plans:
- It’s obvious that websites need to keep updating their UI and other functionalities to enhance the user perception and overall digital experience.
- In effect, it would mean numerous structural changes on the website. But that would upset your plans because you have set up a crawler keeping its existing code elements in mind. It means the scrapers would need to be changed too.
- Hence, you will need to keep updating or modifying your scraper every now and then because the slightest change on the target website can crash your scraper or at least give you incomplete and inaccurate data.
- Dealing with the constant changes and update on target website is a major challenge in web scraping.
2. HoneyPot Traps
Websites which store sensitive and valuable data would naturally put in place some mechanism to protect their data as well. Such mechanisms can thwart your efforts for web scraping and leave you wondering what went wrong. HoneyPots are such a trap:
- HoneyPots are mechanisms for detecting crawlers or scrapers.
- It could be there in the form of ‘hidden’ links but can be extracted by scrapers/spiders.
- These links would probably have a CSS style set to display:none. They can be blended by having the colour of the background or even be moved off of the visible area of the page.
- As soon as your crawler visits such a link, your IP address can be flagged for further investigation or even be instantly blocked.
- The other way used to detect crawlers is to add links with infinitely deep directory trees.
- It means that one would need to limit the number of retrieved pages or limit the traversal depth.
3. Anti-scraping Technologies
Websites having large chunks of data that they don’t want to share with anyone would try and employ anti-scraping technologies. If you are not aware of it, you can end up being blocked. Here’s all you need to know:
- Websites such as LinkedIn, Stubhub and Crunchbase which fear aggressive scraping naturally tend to use powerful anti-scraping technologies which can defeat any crawling attempts.
- Such websites use dynamic coding algorithms to prevent bot access and implement IP blocking mechanisms even if one conforms to legal practices of web scraping.
- It’s quite challenging to avoid getting blocked and requires working out a solution that can work in the face of such anti-scraping mechanisms. Developing such a tool that can work against all odds is extremely time-consuming and not to mention, costly!
4. Data Quality
There are various ways to get data but what matters is how accurate and clean the data is. So you may be able to extract web data but it may not be of much use if there are errors or the data is incomplete. Here’s what you need to keep in mind while chasing data:
- At the end of the day, you need clean and ready-to-use data. Hence, data quality is the most important criterion from a business perspective.
- You want to use data for a particular business decision and for that you need high quality data on a consistent basis. Particularly when you are scraping the data at a scale, it is even more critical because you cannot afford to get inaccurate data at the end of the process.
- Data quality will determine whether the project will see the light of the day or you will need to shelve it and give up your competitive edge.
- Unless you can work out a way to get high quality data on a consistent basis, your web scraping mechanisms will not be much fruitful and useful.
How can I start web scraping?
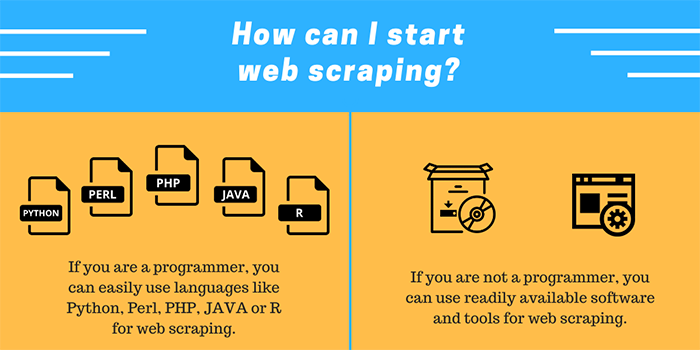
At this point, you’re probably wondering:
“Ok, I’m ready to try web scraping. How do I start?”
1. Coding your own
- This is DIY option. It means that you will have to code a scraper on your own.
- You can use some easy-to-use open source products that can help you get going.
- Then you need a host that can enable your scraper to run round the clock.
- You also need robust server infrastructure that can be scaled up to cater to your requirements. It will also be needed to store and access the extracted data.
- The key advantage is that the scraper is custom-made and hence you can extract the data as you want. In other words, you have absolute control over the process.
- On the other hand, it requires massive resources to do it yourself in this way.
- It will also require constant monitoring as you may need to make changes, modifications and update your system from time to time.
- For simple, one-time project, this may actually work!
2. Web Scraping Tools & Web Scraping Service
- Well, here all you need is to leverage the already existing tools in the market.
- You can invest a bit and explore how you can harness the web scraping tools/software/service available.
- If you can find out a truly viable option in this segment that is affordable and scalable, you can actually benefit from the power of web scraping in much quicker and more efficient manner.
- It will depend on how much you can spend, whether you would like to opt only for free tools or how much data you need to scrape. Accordingly, you can identify the tools and see how it goes.
- You can also explore ProWebScraper. It’s a free web scraping tool that can allow you to scrape the first 1000 pages for free.
3. Freelance Developer
- Well, there’s also a middle path that you can try!
- You can get hold of a freelance developer and get him to work out web scraping tool for your specific needs.
- This will set you free in a way either from DIY stress as well as the significant investment that you may need for tools.
- Provided you can spot such a freelance developer who can understand your needs and conjure up something worthwhile, it’s worth a shot!
Free Web Scraping Tools
Let’s say you are a bit tied up financially or don’t want to invest into the tools at the moment, you can still explore a few free tools and see if it works for you. Here’re a couple of free tools that you can try out:
1. Scraper (Chrome Extension)
- It’s a chrome extension for scraping simple web pages.
- It can extract data from tables and convert it into a structured format.
- It is a simple tool but quite limited as a data mining extension tool. It can help you in online research when you need to get data into spreadsheet form quickly.
- If you are an intermediate or advanced user comfortable with XPath, it’s an easy-to-use tool that you can have in your kitty!
2. Scrapy (web scraping framework)
- Scrapy is an open source collaborative framework that can help you scrape the data you need to fetch from different websites.
- It’s basically an application framework for crawling websites and extracting structured data that you can use for a diverse range of applications such as data mining, information processing or historical archival.
- Compared to all other open source tools, extracting data from web pages using Scrapy is way faster. Therefore, it’s perfectly suitable in the case of bulk data scraping requirements. It’s efficient, scalable and flexible.
- You would also like it for built-in support for generating feed exports in multiple formats (JSON, CSV, XML) and storing them in multiple backends. (FTP, S3, local filesystem)
- It runs on Linux, Mac OS and Windows systems.
Summing it Up
As you can see, web scraping is a powerful technique to extract web data that can help you get a competitive edge over your peers or competitors. With the help of web scraping, you can get clean, actionable web data that can power your business intelligence leading to unlimited growth potential.
All you need to do is start exploring web scraping tools at the earliest.
If you put in some efforts, there are ways to get started in terms of web scraping. There are tools which beginners can use. To start with, there are free tools as well which you can harness.
Well, what are you waiting for then?
Take a plunge into web scraping and leverage the power of data for your business or any other enterprise!