What is web scraping?
Web scraping is a way of extracting web data. You might wonder why one would need to extract web data.
Well, the reason is that businesses have increasingly grown data-driven. It is impossible to make a business decision without consulting the latest data on the subject. Moreover, with the growth of Internet, massive amount of data is getting created. More than 200,000 web pages get added on a daily basis.
However, accessing this data may be easy but downloading is not. It would be nearly impossible to copy and paste it manually.
This is where web scraping comes in.
Web scraping does not only enable you to extract web data but also automates it.
With the help of web scraping, you can download and save web data that you need for your specific purposes. It could be for market research, price monitoring or competitive analysis.
With the help of web scraping, you can scrape data in your own way. You can also save it in a format of your choice- CSV, JSON etc.
The good part is that web data here implies not just textual content but any kind of content- images, URLs, email ids, phone numbers etc.
Web scraping can automate scraping of web data and help you gain a competitive edge over others. It is not just automated but also fast and easy!
You might wonder if it is allowed to scrape data in this way.
Just read on…
Is web scraping legal?
This is the big question, isn’t it?
Well, this is tricky because it could be legal in certain cases and it could invite legal trouble if you are not too careful.
Therefore you need to consider the most important legal aspects and carefully go about web scraping.
To start with, every website has its robots.txt. It contains rules and regulations regarding how the bots should interact with the website. As long as you follow these rules, web scraping can remain a legal exercise.
The next is crawl rate. You should follow a reasonable rate of crawling. Follow a crawl rate of 10-15 seconds per request. If you get too aggressive in crawling, you can get blocked.
If there is an API provided, you should use that in order to access data. Once you follow this, you will be able to avoid legal trouble.
You should also take into consideration the Terms of Service. If ToS specifies that you cannot scrape certain data and you still go ahead and scrape it, you have exposed yourself to legal problems. So respect the ToS and you will be fine.
You should not hit the server too frequently. The server may go down because of this and affect the functionality of the website. Any activity that affects the functionality of a website can attract legal action. So maintain a time gap between two efforts to access web data.
As long as you scrape the public data, you would be safe in legal terms. If you go ahead and scrape data which is not public, you are exposing yourself to legal action.
In short, take care of these few vital things and you would be mostly safe from legal trouble and would be able to continue to enjoy scraping web data.
Web Scraping with Google Sheets
If you want to leverage web scraping, you would need to have in-depth understanding of HTTP requests, faking headers, complex Regex statements, HTML parsers, and database management skills.
In order to make this work, you can make use of programming languages that make the task that much easier. A language like Python gives you access to libraries like Scrapy and BeautifulSoup which make scraping and parsing HTML a cinch.
However, Python could turn out to be quite difficult to master for you. So all you got to do is use a few formulas in Google Sheets instead. The reason why Google Sheets should be used is that it enables you to easily and quickly extract data from any given URL. This is magical because it would take hours if you try to do it manually.
For those of us who cannot master programming overnight, Google Sheet is a just a blessing. It offers a variety of useful functions that anybody can make use of in order to scrape web data.
Without writing any code, you can scrape any information from a website. It could be stock prices, site analytics etc. You can do it without any manual labour or knowledge of programming languages.
By making use of some of the Google Sheets’ special formulas, you can easily extract whatever information that you need from a website and fetch it in your Google Sheets.
The following are the functions that you can make use of for web scraping using Google Sheets:
- ImportFEED → for scraping data from RSS feed
- ImportHTML → for scraping data from table and list
- ImportXML → for scraping data from structured data types
These functions will extract data from websites based on different parameters provided to the function.
3 ways Scrape Website Data With Google Sheets
1. Web Scraping using ImportFeed:
Overview:
- You can make use of Google Sheets IMPORTFEED formula to import RSS or ATOM feeds, that in human-readable format in a Google Doc Spreadsheet.
- In order to keep track of the latest contents from your favorite blogs, all you got to do is create your own feed reader. With IMPORTFEED function in Google Sheets, it would be easily possible for you to achieve this.
Syntax:
IMPORTFEED(url, [query], [headers], [num_items])
URL
- The URL of the RSS or ATOM feed, including protocol (e.g. http://).
- The value for URL must either be enclosed in quotation marks or be a reference to a cell containing the appropriate text.
query [ OPTIONAL – “items” by default ]
- It specifies which data is to be fetched from url.
- For the list of available query options, check out this link.
headers [ OPTIONAL – FALSE by default ]
- Whether to include column headers as an extra row on top of the returned value.
num_items [ OPTIONAL ]
- For queries of items, the number of items to return, starting from the most recent.
- If num_items is not specified, all items currently published on the feed are returned.
Frequency: By default, data updates every 2 hours.
Example:
In this example, we will create RSS feed for website.
Step 1:
Open Blank Google Spreadsheet.
Let’s Create a Feed for website → searchenginejournal,
Below is RSS feed URL for searchenginejournal.com: http://feedpress.me/searchenginejournal
Step 2:
Here we want to import data into the cell B3, which therefore becomes the destination to key in the IMPORTFEED formula.
Formula: =ImportFeed( “http://feedpress.me/searchenginejournal”)
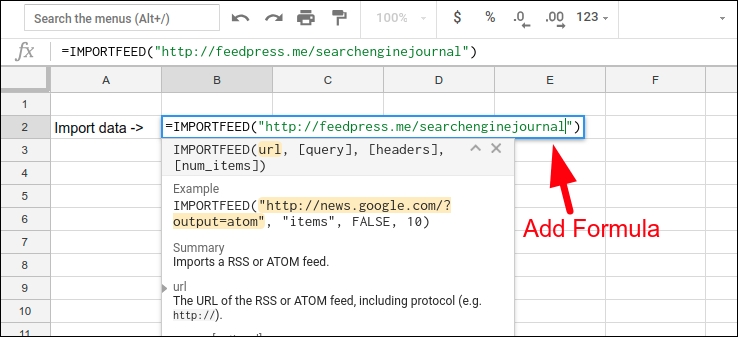
After writing above-mentioned formula, click Enter to get output.
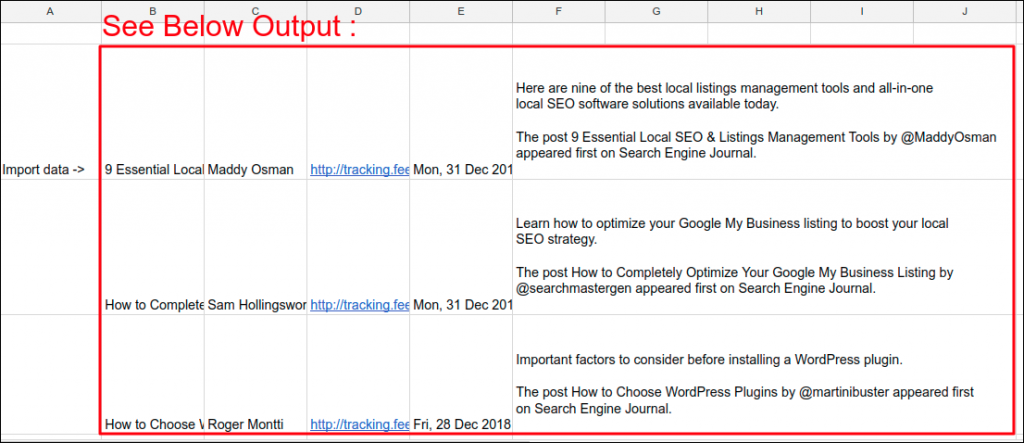
Output:
Once Google Sheets loads the data, we’ll notice that the data extends from the cell B2 to right and also further down.
2. Web Scraping using ImportHTML
Overview:
- ImportHTML can import data from a table or list within an HTML page.
- ImportHTML enables you to import data from table or list from an HTML page into your Google Docs Spreadsheet.
- The importHTML is used to import live data into Google Spreadsheet like Yahoo Finance data or Google Finance data to Google Spreadsheet.
Syntax:
IMPORTHTML(url, query, index)
URL
- The URL of the page to examine, including protocol (e.g. http://).
- The value for URL must either be enclosed in quotation marks or be a reference to a cell containing the appropriate text.
Query
- Either “list” or “table” depending on what type of structure contains the desired data.
Index
- The index, starting at 1, which identifies which table or list as defined in the HTML source should be returned.
Frequency: By default, data updates every 2 hours.
Example:
In this example, we will scrape financial data from web using importHTML function.
So, let’s get started:
Step 1:
Open a new Google Spreadsheet.
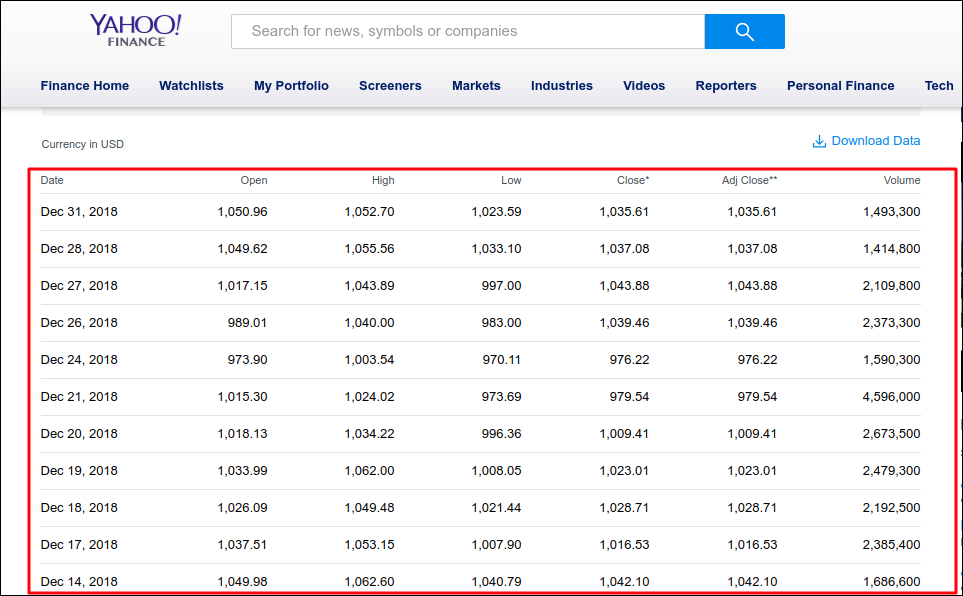
We are extracting financial data from yahoo finance. URL is given below:
https://finance.yahoo.com/quote/GOOG/history?ltr=1
Step 2:
To extract data table from webpage, we are using formula mentioned below:
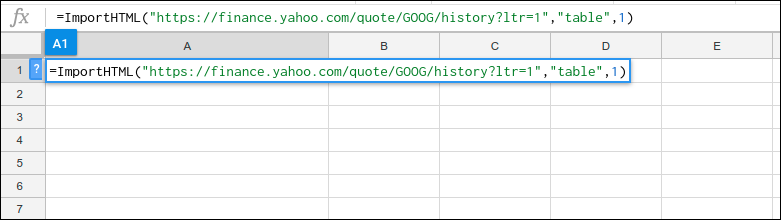
Formula:
=ImportHTML(“https://finance.yahoo.com/quote/GOOG/history?ltr=1″,”table”,1)After writing above formula, click Enter to get output.
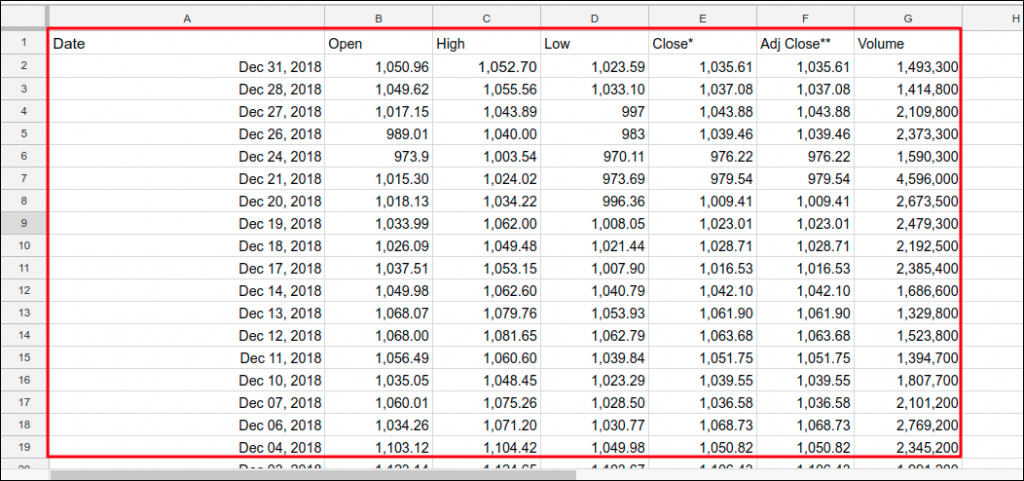
Output:
3. Web Scraping using ImportXML
Overview:
- It can import data from any of various structured data types including XML, HTML, CSV, TSV, and RSS and ATOM XML feeds.
- It can be faster and more convenient than using Screaming Frog or other tools, especially if you only need to extract data for a handful of URLs.
- ImportXML helps you import data from web pages directly into your Google Docs Spreadsheet.
- It works like this. We can now take a look at a page, decide what information we want by looking in the source code, finding the HTML element and by using Xpath we can extract it.
- The ImportXML guide for Google Docs has been written to primarily empower SEOs, SEMs and digital professionals across the world to create their own tools.
Syntax:
IMPORTXML(url, xpath_query)
URL
- The URL of the page to examine, including protocol (e.g. http://).
- The value for URL must either be enclosed in quotation marks or be a reference to a cell containing the appropriate text.
Xpath_query
- The XPath query to run on the structured data.
Frequency: By default, data updates every 2 hours.
Example:
Prerequisites:
- To scrape web data with importXML, it is imperative to use xpath query.
- So, if you don’t have basic idea about XPath, you can study the examples given below to learn XPath.
- // – this means select all elements of the type
- //h3 – this means select all h3 elements
- [@class=”] – this means only select those elements that meet the criteria given – Example: look for H1
- //h3[@class=’storytitle’] – this means only select elements that look like:h3 class=”storytitle”Title/h3
- For more information on XPath, see http://www.w3schools.com/xml/xpath_intro.asp.
- Now you are ready to extract data using ImportXML.
In this example, we extract all the links from webpage with help of ImportXML function.
Step 1:
Open a new Google Spreadsheet.
We will extract all the links from a webpage mentioned below:
https://prowebscraper.com/blog/50-best-open-source-web-crawlers/
Step 2:
Here, we want to extract all the links from webpage, so our XPath query is:
//a/@href
Let’s understand XPath query by dividing into small parts:
//a → his means select all <a> elements from document
/ → Selects from the root node
@href → select href attributes
Step 3:
Here, in the cell A2 and B2, we have stored the URL and Xpath_query.
So, we will use that cell to refer in the IMPORTXML formula.
Now, implement ImportXML by adding URL and XPath query as given below:
Formula:
A2 : https://prowebscraper.com/blog/50-best-open-source-web-crawlers/
B2 : //a/@href
=IMPORTXML(A2, B2)
or
=IMPORTXML(“https://prowebscraper.com/blog/50-best-open-source-web-crawlers/“,”//a/@href”)
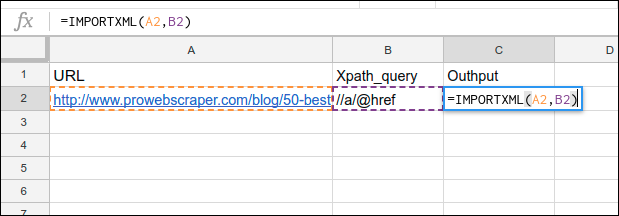
After writing above formula, click Enter to get output.
Output:
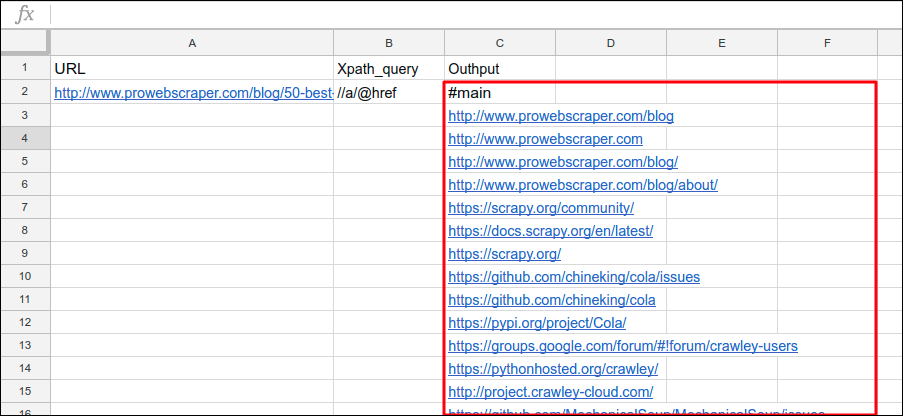
By extracting links in such a way from a website, you can make use of these links to find broken links from your website (for better SEO) and from other websites (for backlink opportunity).
Limitations
While Google Sheets can work out quite well most of the times, it is possible that there would be some hiccups sometimes. As these formulas are unstable, you will sometimes see an error message.
Moreover, it may work for small-scale tasks in terms of web scraping. Unfortunately, it is unsuitable for scraping large quantities of data. In case, you still go ahead and try it, it will probably malfunction or stop functioning.
Whenever you have this kind of a task that involves more than a significant number of URLs, it’s recommended to use more robust and reliable web scraping services.
Conclusion
Web scraping has become an integral part of accessing and processing data for business and other purposes. In one or the other way, you will need to scrape data from the web. However, it is not possible to do so manually beyond a point.
Moreover, you may not be willing to or in a position to invest in paid web scraping tools. At the same time, you still need to leverage web scraping and there is no escape from it either.
In such a scenario, web scraping using Google Spreadsheets can be quite useful and effective. For small-scale web scraping tasks, it can be extremely helpful. Since it is a part of Google, you can easily use it along with other Google services quite seamlessly.
So leverage Google Spreadsheets and scrape away for your customized and specific needs!
Resources
- IMPORTFEED : https://support.google.com/docs/answer/3093337?hl=en
- IMPORTHTML : https://support.google.com/docs/answer/3093339?hl=en
- IMPORTXML : https://support.google.com/docs/answer/3093342?hl=en