In this rapidly data-driven world, accessing data has become a compulsion. Whether you are an ecommerce company, a venture capitalist, journalist or marketer, you need ready-to-use and latest data to formulate your strategy and take things forward.
With the astronomical growth of the Internet, data should not be a hurdle, right?
Well, it’s easier said than done. Yes, the data is readily available on the Internet but it is not available in a downloadable format.
You might wonder how to overcome this limitation and get unlimited and easy access to data in a format of your choice!
Well, this is how it works: most of the data you see on the Internet is available in an unstructured format or call it HTML and hence, you cannot download it as it is. Yes, you can copy and paste it manually. But you may not have the time and energy to do so for the large chunks of data that you need.
Therefore, the only practical solution is to automate the process and scrape the data easily and comfortably. Automating the process of scraping the data is the only way out of this situation wherein there is a pressing demand and yet the unavailability of data.

- Scalable: Handle large-scale scraping needs with ease.
- Robust QA: Hybrid QA process for accurate data extraction.
- Uninterrupted Scraping: residential proxies that never get blocked while scraping.
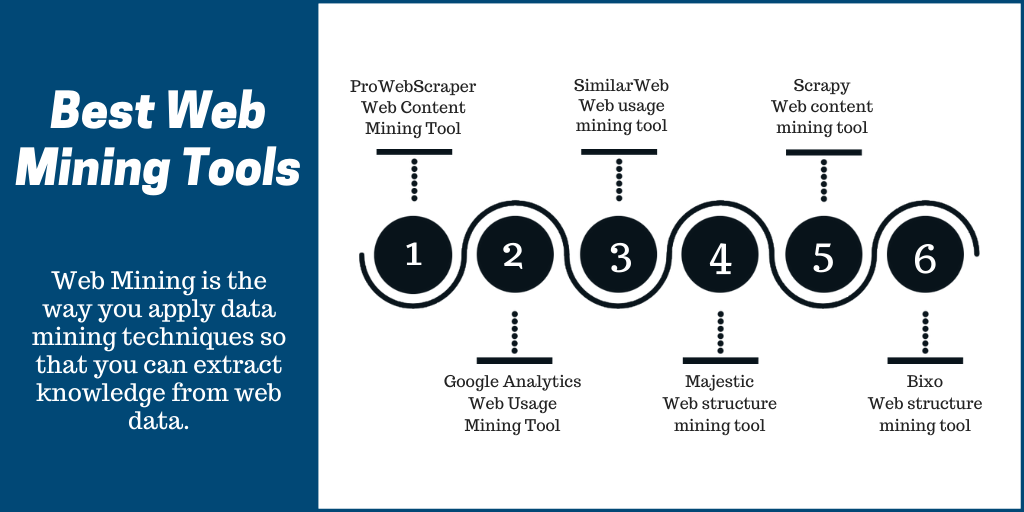
What is web scraping and why do we need web scraping
Since there is a lot of demand for data for market research, price intelligence or competitor analysis etc. the demand for automating the process of scraping the data has also grown. This is where web scraping comes into play. Web scraping is the automated process of scraping the data from the web in a format of your choice.
Why web scraping has become so critical is because of a set of factors. Firstly, the data that you access on the Internet is not available for download. However, you need it downloaded and in a different format. So you need a way to download the data from multiple pages of a website or from multiple websites. Therefore, you need web scraping.
Web scraping is also needed because you have no time to fret over how to download, copy, save the data that you see on a web page. What you need is an easy, automated way of scraping whatever data that you see on the web page and hence web scraping! What web scraping does so well apart from giving you the data that you need is that it saves you hundreds of man hours that you will otherwise need if you try to manually get the data.
At times, there is no API from the source website and hence web scraping is the only way to extract the data.
In this blog, you will get to see a guided tour of how web scraping can be done in a practical way. I will provide you a sort of use case of how PHP can be used for web scraping. If you follow the inputs from this blog, I am sure, you can learn to do it yourself and extract any kind of data from the Internet and put to its best possible use. To make it more relevant as a use case, we will try to scrape data from IMDB!
However, before we proceed, let’s take a look at some of the popular web scraping techniques:
Web Scraping Techniques
Users access and get the data they want in their different ways. Here’s a list of a few:
Manual
This is how most average users get the data from the Internet. You liked an article so you copy and paste it on a word file on your desktop. This is manual and hence slow and less efficient. Moreover, it works for small chunks of data that involves only simple text. If you wish to save images, and other different kinds of data, it may not work quite efficiently.
DOM Parsing
With the help of web browsers, programs can access the dynamic content that the client-side scripts have created. One can parse web pages in the form of a DOM (Document Object Model) tree which is in a way a description of which programs can get access to which parts of the pages. To give you an example, an HTML or XML document is converted to DOM. What DOM does is that it articulates the structure of documents and how a document can be accessed. PHP provides DOM extension.
Regular Expressions
In this case, you define a pattern (or say “regular expressions”) that you want to match in a text string and then search in the text string for matches. It is used a lot in search engines. When one is exploring string information, regular expressions come into play. Regular expressions are a basic tool and can take care of your elementary needs.
In the practical application of using PHP for web scraping, we will use the DOM parsing technique. We will depend on the HTML class of a web page to look for relevant fields where the requisite information is stored.
However, before we move forward, here’s something you must consider every time you indulge in web scraping:
“Don’t forget to read the terms of service of the concerned website from which you want to extract data because you may unintentionally get into an illegal exercise leading to legal trouble.”
Web Scraping Using PHP
We will explore some PHP libraries which can be used to understand how to use the HTTP protocol as far as our PHP code is concerned, how we can steer clear of the built-in API wrappers and in its place, think of using something that is way more simple and easy to manage for web scraping.
What we will try to do here is to write a straightforward scraper with the help of Simple HTML DOM library. It will be possible for you to see how to scrape the data you want using PHP and how the extracted data can be converted into xml file with the help of SimpleXMLElement library as shown below:
1. Simple HTML DOM
- An HTML DOM parser which is written is PHP5+ is useful because it allows you to access and use HTML in a convenient and comfortable way.
- It is PHP5+ compatible.
- It supports invalid HTML.
- You can use it to identify tags on a given HTML page with the help of selectors like jQuery.
- You can get the contents from HTML with a simple single line of code.
2. SimpleXMLElement
- SimpleXMLElement stands for an element in an XML document.
- It is nothing but just an extension that enables you to get XML data.
- What it does is that it converts an XML document into a data structure. It means that you can access and use it like a data structure.
Prior to getting started, it is necessary to take a look at the pre-requisites for extracting web data.
Pre-requisites
- PHP5+ or 7+
- Basic knowledge of PHP (And OOPS concept)
- Basic knowledge of HTML
- Simple HTML DOM Parser
It is imperative that you possess the elementary understanding of HTML as you will need to extract data from a web page which contains a lot of HTML tags.
If you are already aware of HTML and its tags, you can directly go to the practical section of the blog regarding scraping web data.
Understanding HTML
- HTML is a language used for creating web pages.
- It is an acronym for Hyper Text Markup Language
- It uses markup and describes the structure of the web pages.
- HTML pages are basically made of HTML elements
- HTML elements are represented by tags
- There are various tags like “heading”, “paragraph”, “table” etc.
- When an average user accesses a web page, he/she cannot see the HTML tags in a browser. Browsers only use HTML tags to float the content of a web page.
Here is what a simple HTML code looks like:
Example:

In image above:
<!DOCTYPE html>: It indicates that this particular document is HTML5.
<html> : It is the basic element of an HTML page.
<head> : It carries meta information about the document.
<title> : It explains the title for the document.
<body> : It carries the visible page content.
<h1> : It indicates a large heading.
<p> : It stands for a paragraph.
HTML Page Structure:

Please refer to W3Schools Tutorials if you want to know more about HTML tags, id and class.
What will you learn in this tutorial?
- How to install SimpleHTMLDOM
- How to Scrape data from website using SimpleHTMLDOM
- How to store data to xml file
- How to automate script using crontab
1. How to install Simple HTML Dom Parser:
To start with, download Simple HTML Dom Parser from this LINK.
Next, extract zip file Simplehtmldom_1_5.zip and what you will have is a folder called “simple_dom”.
2. How to Scrape data from website using PHP with Simple HTML DOM
Now we come to the application part of the process. Let’s get down to scraping the IMDB website to extract the review of the movie “Avengers: Infinity War”. You can get it here.
Step 1: Create a new PHP file called scraper.php and include the library mentioned below:
<?php
require_once ‘simple_html_dom.php’;
To create a new PHP file, create a new folder called “simple_dom” and include “simple_html_dom.php” file at the top.
Why movie reviews and rating matter is because these can be used to create the necessary database for sentiment analysis, text classification etc.
Since there are countless reviews in a website like IMDB, it is not possible to get all the reviews by mere copy-paste.
With the help of web scraping, you can get all the reviews in an automatic fashion and save it in xml file.
Now, we will extract the following data from the website:
- Rating stars – The users’ rating stars of the film.
- Title of reviews – The title of the users’ review.
- Review – The content of the review.
Here’s how all these fields are arranged. Take a look at the screenshot:

Step 2: Extract the html returned content from the website.
What you need to do is use file_get_html function to get HTML page of the URL.
URL = https://www.imdb.com/title/tt4154756/reviews?ref_=tt_ov_rt .
<?php
require_once 'simple_html_dom.php';
//get html content from the site.
$dom = file_get_html('https://www.imdb.com/title/tt4154756/reviews?ref_=tt_ql_3', false);Step 3: Scrape the fields of the reviews
Now the fun starts. We will make use of the HTML tag and scrape the data items mentioned earlier, like rating stars, title of the review and reviews with the help of Inspect element.
This is how you can find out the class of the tag with the help of following step:
Go to chrome browser => Open this url => do right click => inspect element
NOTE: If you don’t use chrome browser, go through this article
Next, we will scrape the requisite information from HTML based on css selectors like class, id etc. Now let’s get the css class for title, reviews and rating stars. All you got to do is right click on title and select “Inspect” or “Inspect Element”.

As you can see, the css class “review-container” is applied to all <div> tags which contain titles, rating stars and reviews of users. This will be useful in the process of filtering the field from the rest of the other content in the response object:
Next, we will scrape all those fields with the help of that class and a for each loop, as is shown below:
//collect all user’s reviews into an array
$answer = array();
if(!empty($dom)) {
$divClass = $title = '';$i = 0;
foreach($dom->find(".review-container") as $divClass) {
//title
foreach($divClass->find(".title") as $title ) {
$answer[$i]['title'] = $title->plaintext;
}
//ipl-ratings-bar
foreach($divClass->find(".ipl-ratings-bar") as $ipl_ratings_bar ) {
$answer[$i]['rate'] = trim($ipl_ratings_bar->plaintext);
}
//content
foreach($divClass->find('div[class=text show-more__control]') as $desc) {
$text = html_entity_decode($desc->plaintext);
$text = preg_replace('/\'/', "'", $text);
$answer[$i]['content'] = html_entity_decode($text);
}
$i++;
}
}
print_r($answer); exit;- I used for each loop to get all the data I want and save it to “$answer” array.
- Next, I will print that array and review the output.
Output:
- As you can observe in the screenshot, we could scrape the title (title of review), rate (rating stars) and content (reviews) in array.

Step 4: Store data into xml file using “SimpleXMLElement”
- The next step is to store the output in an xml file. So all we need to do is to convert “$answer” array into xml element.
- In order to do that, we will make use of “SimpleXMLElement” built-in class to convert PHP array into xml element. //function definition to convert array to xml
function array_to_xml($array, &$xml_user_info) {
foreach($array as $key => $value) {
if(is_array($value)) {
$subnode = $xml_user_info->addChild(“Review$key”);
foreach ($value as $k=>$v) {
$xml_user_info->addChild(“$k”, $v);
}
}else {
$xml_user_info->addChild(“$key”,htmlspecialchars(“$value”));
}
}
return $xml_user_info->asXML();
}
//creating object of SimpleXMLElement
$xml_user_info = new SimpleXMLElement(“<?xml version=\”1.0\”?><root></root>”);
//function call to convert array to xml and return whole xml content with tag
$xmlContent = array_to_xml($answer,$xml_user_info); - ⦁ We created an object of SimpleXMLElement and then placed that object into a user defined function called “array_to_xml”.
“$xml_user_info” = It is an object of SimpleXMLElement
“array_to_xml” = It is a user defined function
“$xmlContent” = It is a variable where the data is stored in array format
Step 5: Create an xml file and write xml content to xml file
- Next I created a file called “AvengersMovieReview.xml” and stored “$xmlContent” into this file. // Create a xml file
$my_file = ‘AvengersMovieReview.xml’;
$handle = fopen($my_file, ‘w’) or die(‘Cannot open file: ‘.$my_file);
//success and error message based on xml creation
if(fwrite($handle, $xmlContent)) {
echo ‘XML file have been generated successfully.’;
}
else{
echo ‘XML file generation error.’;
}
?> - At the end of it all, run the whole code and review the output and created xml file AvengersMovieReview.xml.
- See the screenshot of the output and that is the file.

And we completed scraping the data that we needed. Wasn’t it easy to scrape the web data using PHP?
The last bit that you should know: here’s the explanation for Linux basis regarding how to schedule and run this task in the background at regular breaks and in an automatic fashion with the help of Crontab command.
Automating Script Using Crontab
As you would know, Linux server can help you in automatize certain functions and completing the tasks which otherwise require human intervention. As far as Linux servers are concerned, cron utility is something that people prefer in order to automate the way scripts run. For your needs of large data on a daily basis, it can be useful.
Cron is something works well on Linux and Unix environments that take care of scheduled commands which are also called cron jobs configured by the crontab command.
As regards a Linux pc, you can use this script to run it at a specified time of the day with the help of the command “crontab-e”. If you wish to access more information on crontab, read it here: https://www.tutorialspoint.com/unix_commands/crontab.htm
Conclusion
Web scraping has turned into a compulsion for businesses. If you want to carry out market research, you need data. If you want to devise your sales strategy, you need data. If you want to generate leads for your business, you need data. In all possible crucial aspects of business strategy and operation, web scraping can enormously contribute by automating extraction of data.
If you want to scrape large amounts of data for your specific needs, you may encounter the following challenges:
- You may get blocked.
- You may find it difficult to scrape data from a dynamic website
- You may be stuck up dealing with pages scrolling on and on.
Thank heavens, there is a highly efficient and reliable web scraping service like PROWEBSCRAPER to tackle all these challenges and provide you the data you want.
Did you like the article?
Do your feedback, comments and suggestions!
Feel free to reach out for any of your queries!