Are you a researcher in search of books for completing your research paper or book? Are you slapped with a deadline too?
Welcome to the world of research- a lot of data to be accessed in too little time!
Why Archive.org for research?
Research then vs. now
In the good old world, researchers would take their own sweet time and visit libraries and sit for hours and days to sift through the data and information available in several volumes. Moreover, how many libraries will you be able to visit? Making time to visit library and hunt for a single book for weeks is a luxury and a thing of the past. Some libraries may be located in different countries altogether. Not a viable option, is it?
Guess what, suddenly, the world has changed. Everything we held dear has gone online, including access to books. Now you search for books online and scanned/ebooks are all you need. However, it is trickier searching for books online. A plain Google search for ebooks on the topic of your research may not yield desired results. You may get a lot of ebooks that you DON’T want!

- Scalable: Handle large-scale scraping needs with ease.
- Robust QA: Hybrid QA process for accurate data extraction.
- Uninterrupted Scraping: residential proxies that never get blocked while scraping.
Scattered Data vs. One Source
Let’s say you are working on the correlation between economic growth and employability. You want to access the Congress records/reports wherein there’s data and statistics regarding the economic conditions prevalent in the US. You want to access Fed documents to study the policy initiatives from time to time. In addition, you want to access early issues of journals which are available only in JSTOR.
Typically, you will search for this in Google in different ways and you will access different websites of the kind mentioned above. However, you will search a lot and find a little which is of value with respect to your research.
This is where a site like Archive.org comes into play.
What’s Archive.org and how can it help researchers?
In layman’s terms, Archive.org is a non-profit library of millions of free books, audio books, movies, software, music etc. from where you can get all the books and other media you want. Whether you are looking for ebooks, audiobooks of Harry Potter or some Urdu books, you can find it all here. All the documents our particular researcher who needs related to Congress, Fed and JSTOR back issues are easily available at Archive.org!
Then what’s the hitch?
The problem, however, is that you have a timeline for your research and you are running short of time even for reading and analyzing the data. Add to this the time required for penning down the findings, and you have a perfect recipe for panic!
Manual Download/Access of Archive.org Resources
If you manually try to download the books and other media you need from Archive.org, it will take ages. All you hope and pray for is some way to access and extract the books you want in an automated fashion.
No worries.
Here’s the good news: you can use web scraping tools to access and extract books and other media for your research. Rest assured, it will be quick and work like magic!
Wondering how you can do it?
Here’s how you can capitalize on web scraping for extracting books and other media from Archive.org:
But before you plunge right into web scraping for Archive.org resources, you must come to terms with the challenges of manually accessing the said resources and how web scraping is not an option but a necessity.
Challenges of Accessing Data from Archive.org
Of course, you know how difficult it is to extract the books you need from Archive.org. But it would be good to understand the technical difficulties in layman’s terms and the reason why web scraping can be such a great advantage for a researcher!
- First of all, there are millions of books and other resources as mentioned earlier. As much as it is a treat for the researcher, it also poses a big challenge to sift through the maze of millions of books and access and download the ones you need.
- Secondly, when you search with a key word, Archive.org, it will generate hundreds of pages with books and other resources for you to consider for download. It’s obvious, you cannot visit each page one by one and see what each page contains. Even if you embark on this laborious task, you cannot even hope to complete it before the turn of the century!
- For each topic/subtopic, you can get at the most 50 book results per page and at the most 200 pages. In other words, doing this manually is not only a nightmare but also inadequate for your research purposes because you will not be able to access the docs you want or may not even be able to choose the right books you need.
- These are the reasons precisely why web scraping can help you extract the books you need in bulk in an automated fashion. With web scraping, you will not need to invest your valuable time and energy on manually downloading it as the process will become automated. In no time, you will be able to access the books you need in a hassle-free manner.
How to Scrape Books and Other Media from Archive.org – A Step-by-Step Guide
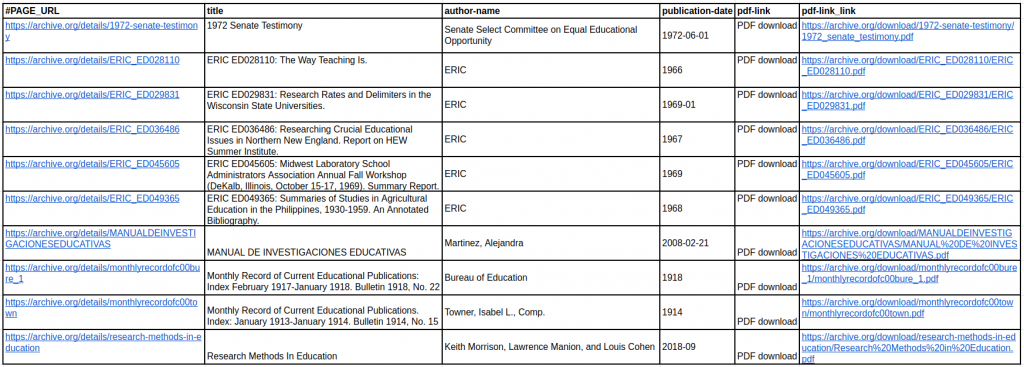
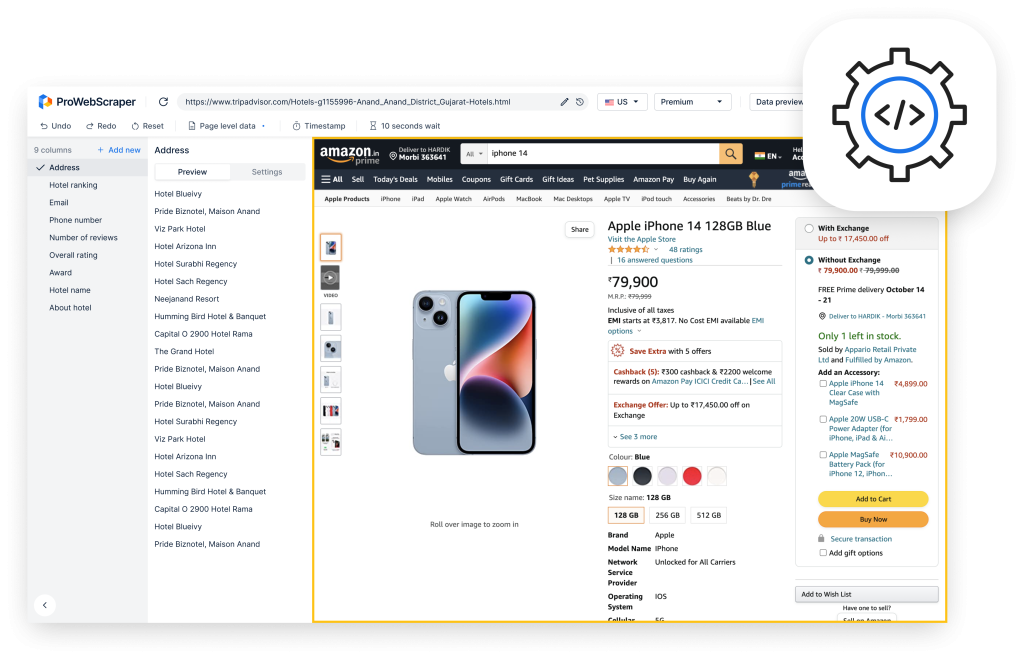
In this tutorial, we will learn to build a scraper which will extract title, author name, publication date and PDF file link from Archive.org. We’ll build this scraper using ProWebScraper.
This scraper will extract the following fields from Archive.org :
- Title
- Author Name
- Publication date
- PDF File Link
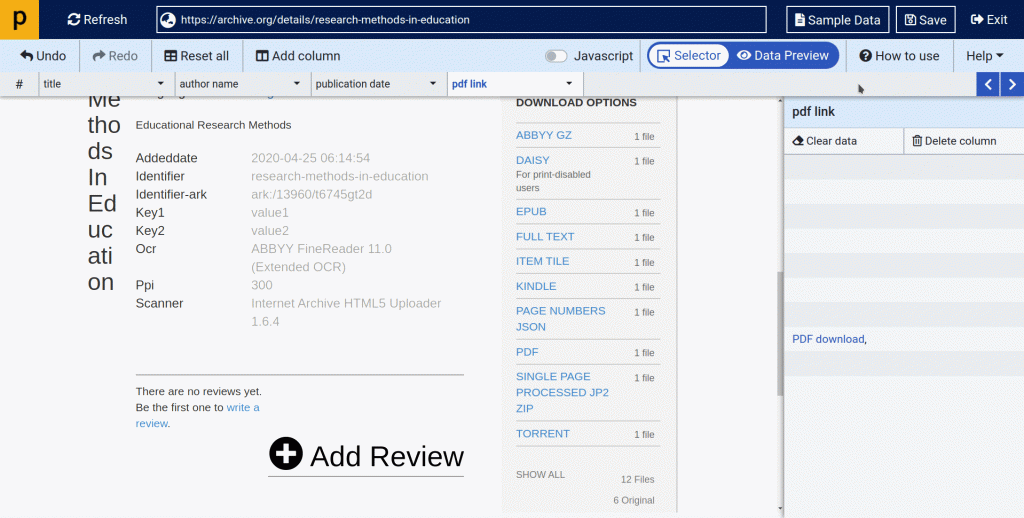
Below is a screenshot of the data we will be extracting from archive.org.
Well, let’s get started.
To make it truly easy and simple for you, we have worked out a three-step process for extracting the data you need from Archive.org.
- Create a Free Account on ProWebScraper
- Create and Configure a Scrapers
- Download Your Data
Step 1: Create a Free Account on ProWebScraper
All you need to do is to go to Prowebscraper.com and create a free account. With this free account on ProWebScraper, you can scrape 1000 pages for free.
After you’ve logged in ProWebScraper, you’ll be taken to the scraper tab. Here’s what it’ll look like:
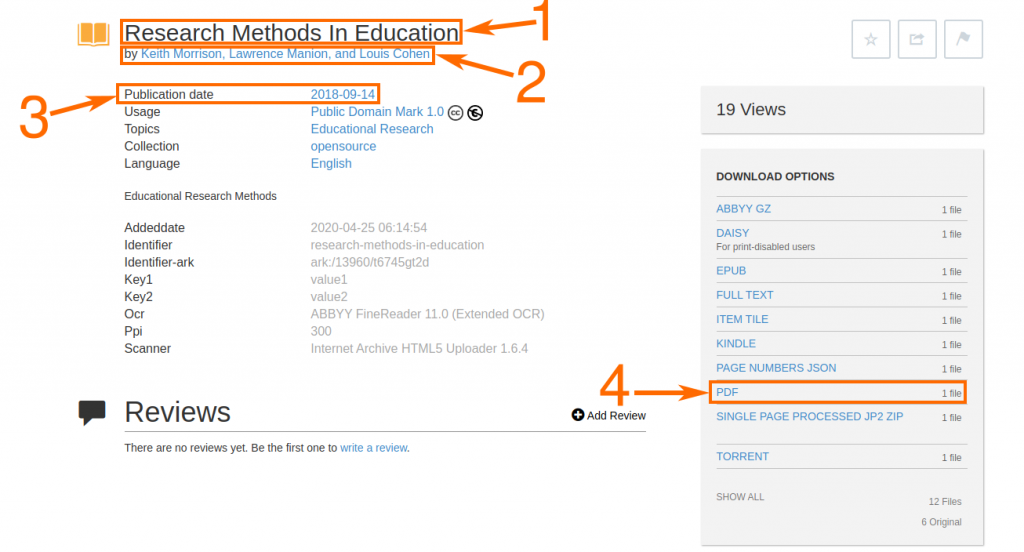
Step 2: Create & Configure a Scraper
- Once you have created a free account, you are now close to getting the data you need.
- In this case, we need to create 2 scrapers- the first one to get the URL of all books from the book listing page and the second one to scrape final data [title, author name, pdf link, etc..] from book detail page.
- Now, we will start creating and configuring our first scraper by entering a URL of the page where all books are listed.
- Let’s take a look at the entire process, step-by-step:
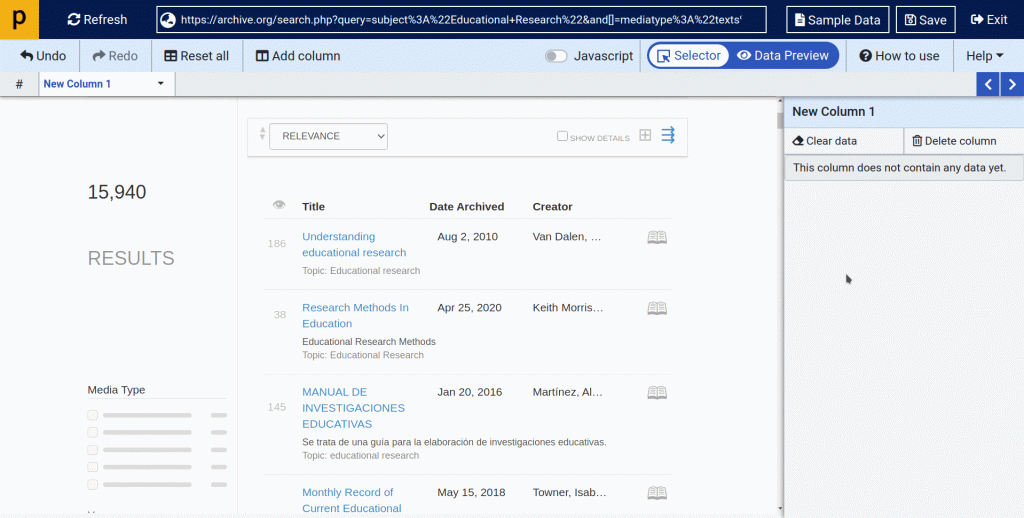
(2.1) On Scraper tab, we will start by copying and pasting the URL of the Archive.org listing page such as https://archive.org/search.php?query=subject%3A%22Educational+Research%22&and[]=mediatype%3A%22texts%22 and click on “Go” to load the page.

(2.2) Once the webpage is loaded at ProWebScraper, you can start configuring the scraper.
- Now, you can start fetching the data you need. All you need to do is just click directly on the different items of information.
- To extract the list of the books, just click on the book title. You can see how the data you clicked on is now showing on the current selection panel.
- To capture the URL of these data points, go to column settings => click on “Capture this link’s URL” to enable it, which will have a checkmark next to it when enabled.
Note: To name this data point, just double click on the name of that column.
- Once you have selected all the data points, click the “Save” button to save your scraper.
- Name your Scraper, and then click Save and run.
Note: You should keep “is this listing page” enabled, as this scraper is for listing.
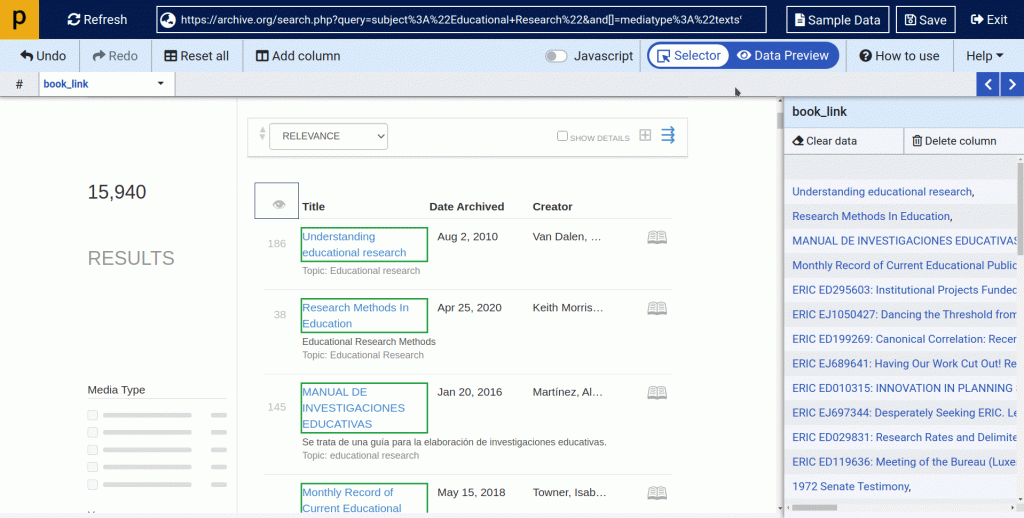
(2.3) Now we will create a second scraper.
- In this scraper, we will scrape final data from book detail page such as: https://archive.org/details/research-methods-in-education
- click on button New Scraper, enter the above-mentioned URL, and click Go.
- Once the webpage is loaded at ProWebScraper, you can start configuring the scraper.
- Below is an example of how you will select a title, author name and publication date using point and click selector.
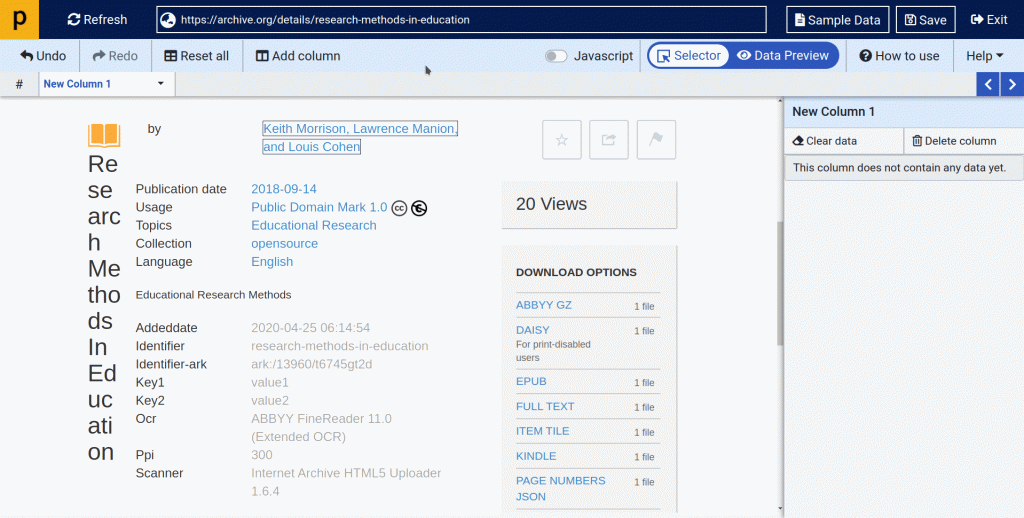
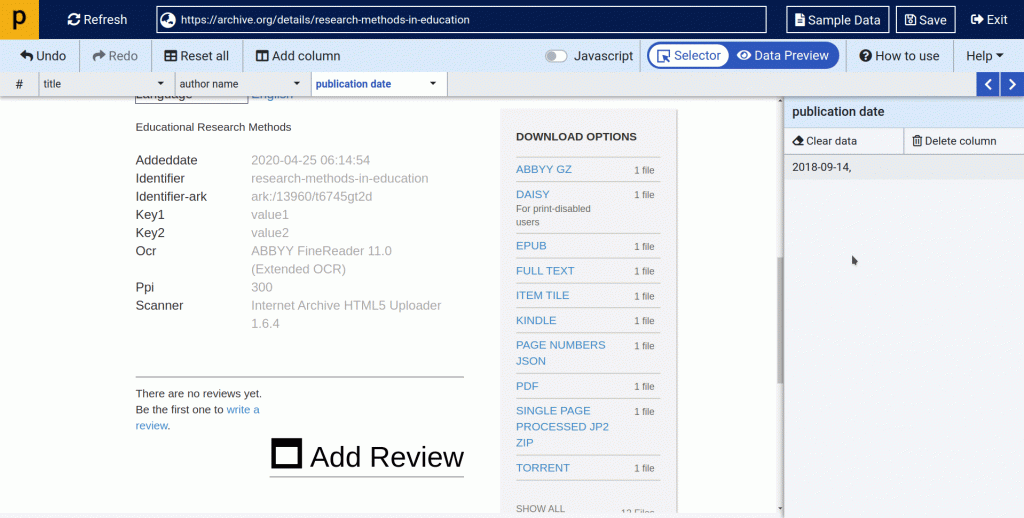
(2.4) Now let’s see how to scrape PDF links.
- On the Archive.org, there are many “DOWNLOAD OPTIONS” available to get the book you need.
- In this tutorial, we will focus on getting the pdf file. So we will try to scrape the PDF file link. To get it done, we need to apply regex as there are too many links.
- To do this, we simply need to “Add Column”, then click on “PDF”.
- To scrape the pdf link, apply “Capture this link’s URL”.
- Now you see that by default ProWebScraper algorithm selects all the available DOWNLOAD OPTIONS.
- As we only want to scrape pdf file Go to column settings > Set Regular Expressions
- Fill below details at dialog box :
- Match a word : PDF
- Fill below details at dialog box :
- Let’s take a look at how it works:
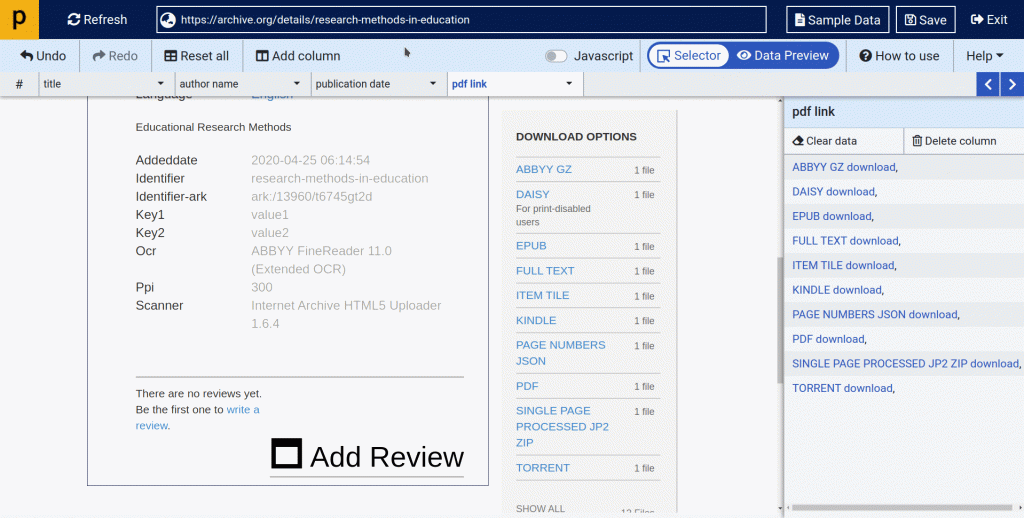
- Once we have selected all the data points, simply click on the “Save” button to save your scraper.
- For now, you need to keep the option ”is this listing page” disabled, as this scraper is for details.
- Enter name of your scraper, and then click Save and run.
- Once the scraper is saved, it will take you to the scraper dashboard.
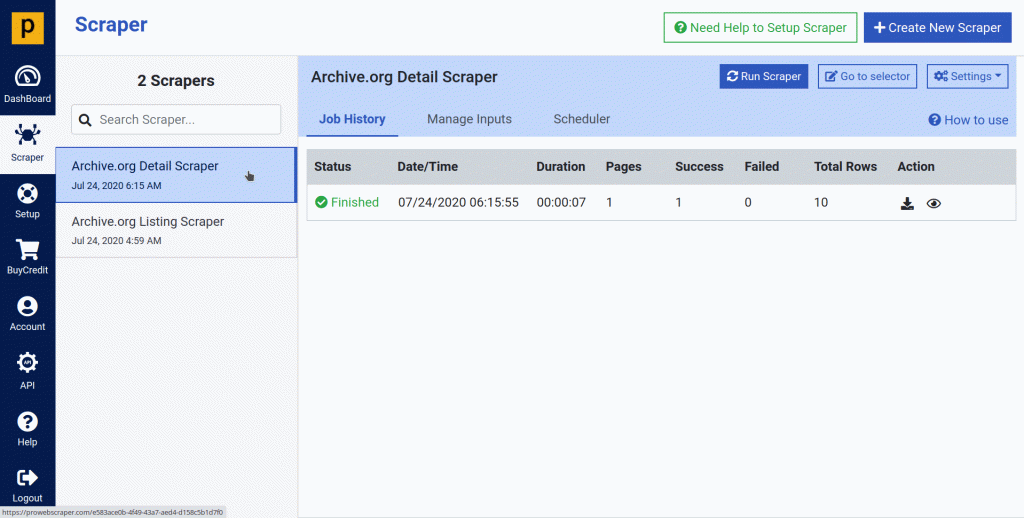
(2.5) Now we have created 2 scrapers, one is for scraping a list of books and another is to fetch final data from a book detail page.
- Typically, it’s tricky to get data from all detail pages. But we will use chaining functionality to scrape final data from all listed books.
- Chaining functionality will take all book detail page links from Archive.org Listin Scraper and give as input to Archive.org Detail Scraper.
- To apply chaining,
- Go to the ‘Manage Input’ tab of your Archive.org Detail Scraper.
- Change the Input Source dropdown to URLs from another Scraper.
- Set the Parent Scraper to Archive.org Listing Scraper.
- Select the book_link that has the extracted URLs.
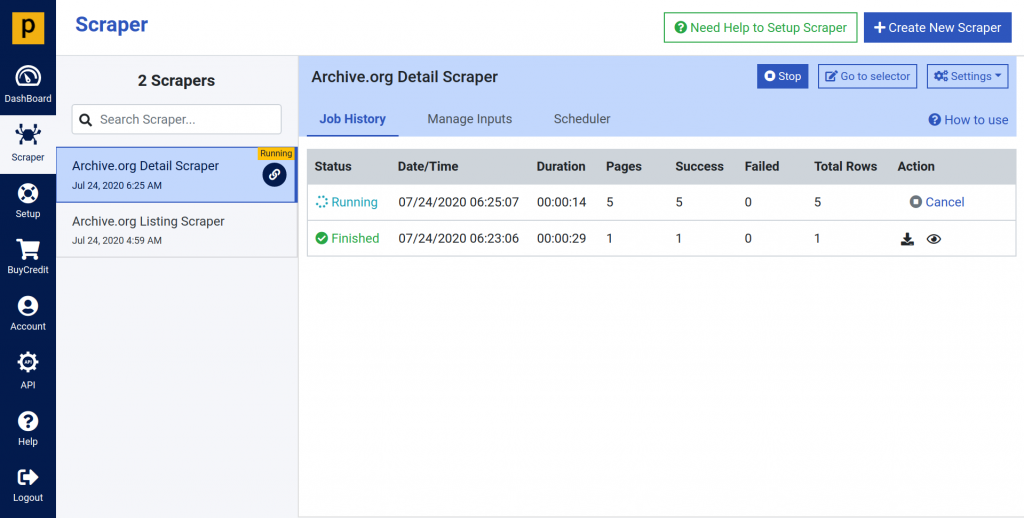
- Now run the detail scraper again to scrape full data.
- You can see that after apply changing, scraper scraped data from 5 pages and it’s still running.
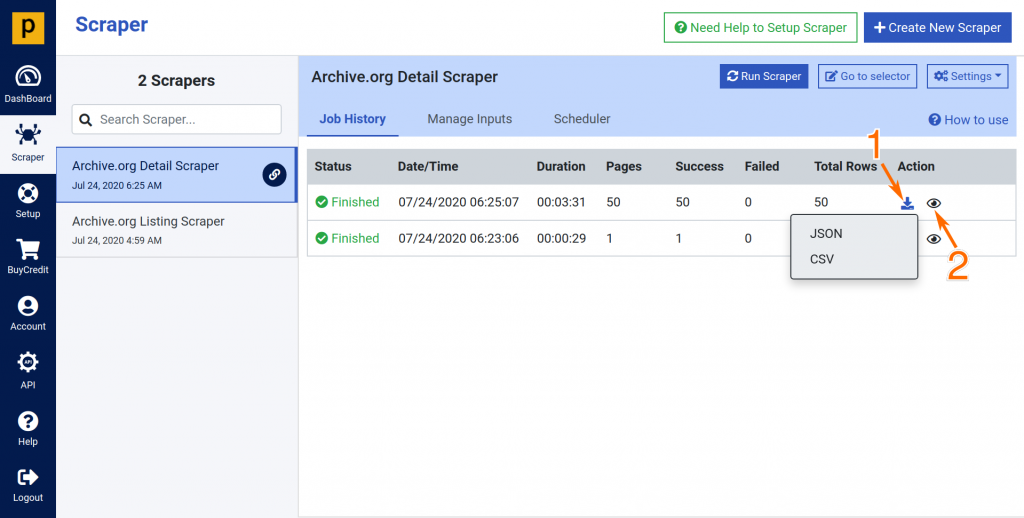
Step 3: Download your Data in CSV or JSON
- After the scraper successfully finished, your data will be available for download within the Scraper Dashboard.
- You can easily access the data from the Job History tab. You can see the previous runs including the latest one with the results at the top.
- The data will be available for download (1) in JSON or CSV format.
- You can see the “Data Preview” of scraped data (2).
Sample Data File (CSV Format) :
https://drive.google.com/file/d/1lij9d6HWwuKgjWfFvIhmxpJRm21_fLS6/view?usp=sharing
Sample Data Preview: