
Have you heard about your competitors scraping prices? Do you want to start price scraping too? But, before it, you must know why price scraping is necessary.
Why Should You Scrape Prices from Websites?
Its primary use of it is competitor price monitoring.
An Insider report mentions that the e-commerce platform Amazon changes its product price every ten minutes. You will see the price changing on Amazon 2.5 million times a day.
Amazon does this by constantly scraping the products’ prices from other e-commerce platforms and then changing the cost to the cheapest on their platform. With this strategy, they have offered the products to consumers at the lowest price. It helped them boost their sales by 25%.
Also, as an e-commerce manager, you must monitor the market price of the products like what discount competitors are giving and at what price they are selling. You can do this through price scraping. After you know the competitor’s pricing strategies, you can set your price based on that and drive the customers towards you. Simple!
The next advantage of price scraping is MAP compliance monitoring. MAP stands for Minimum Advertised Price. MAP contract says that sellers can’t sell the products below a specific price to gain the customer base. But 20% of authorized & 50% of unauthorized sellers advertise products below MAP on their online shops or marketplace like Amazon.
So, MAP compliance became very necessary for the brands to check that their sellers weren’t hurting the prestige of their brand. When the sellers do not comply with the MAP, the brand can penalize them and take legal action.
Hence, to maintain fair competition across all distribution channels, MAP is crucial for the brands. It also protects their positioning and reputation in the market. So, as a brand, it becomes vital to scrape prices from all platforms to know at what price the sellers are selling your product or if they are violating the MAP compliance.

- Scalable: Handle large-scale scraping needs with ease.
- Robust QA: Hybrid QA process for accurate data extraction.
- Uninterrupted Scraping: residential proxies that never get blocked while scraping.
Challenges of Scraping Prices from Websites
It may sound easy, but price scraping also has many challenges like any other process.
1. Product variation
Every product varies based on size, color, memory, and other aspects. These variations of the products are sold at different prices in the market. So, when one product has many variations, it becomes a challenge to scrape so many prices at once.
2. Data consistency/ Quality
A scraper needs to give you the real-time and accurate price of the product. Suppose we are scraping the price of a mobile phone. A result shows $12,000 from Amazon at 10 am. After that, Amazon can change the price, too, let’s say, $11,500. On the same day, if I rerun the scraper, it should show me the new price of the mobile phone, i.e., $11,500. Thus, a scraper should show the real-time price while scraping data.
Another big challenge is when you enter a URL for scraping; besides the original product, many other products are also visible in the suggestions. The scraper can see the prices of these products as well. So, it may get confused about which price to scrape from the multiple prices available on the screen and give us incorrect data on the prices.
The scraper also needs to provide all the data in the same currency. It cannot give one result in the dollar, another in euro, and another in rupee. There can be no comparison between these currencies then.
So, the scrapers need to be advanced to be consistent with the data quality and a structured format.
3. Blocked while scraping
When you try to scrape the prices, websites like Walmart and others identify your IP address and block it since they don’t want to reveal their prices. So, getting blocked while scraping is another major challenge encountered during price scraping.
4. Scalability
We see every product sold on multiple platforms. And all these products have their variations.
For example, I want to scrape the price of school water bottles. If I sit to scrape prices for this, I’ll get over 50,000 products with variations from at least ten different websites. How can a single server scrape thousands of web pages every day? For this, distributed web crawling needs to be set up, which becomes another challenge for us.
So, when there are so many challenges, how are different companies still managing to scrape prices? Tools like ProWebScraper are capable of overcoming all these challenges. How? Let us see.
Here is an example where we will build a Declutter scraper to scrape job data like network, size, color, price, and more.
How to Scrape Prices From Websites? A Step-by-Step
We can scrape the data through a few simple steps, and the exciting part is none of these steps require coding experience. So, a non-technical person like you and I can also scrape data from various websites through simple clicks.
Step 1: Enter URL
Step 2: Configure Scraper to extract a price
Step 3: Save and Run Scraper
Step 4: Bulk page scraping
Step 5: Download the data
Step 6: Schedule a scraper
Let us study these steps in detail.
Step 1. Enter URL
First, find the page where your data is located—for instance, a product page on Decluttr.com.
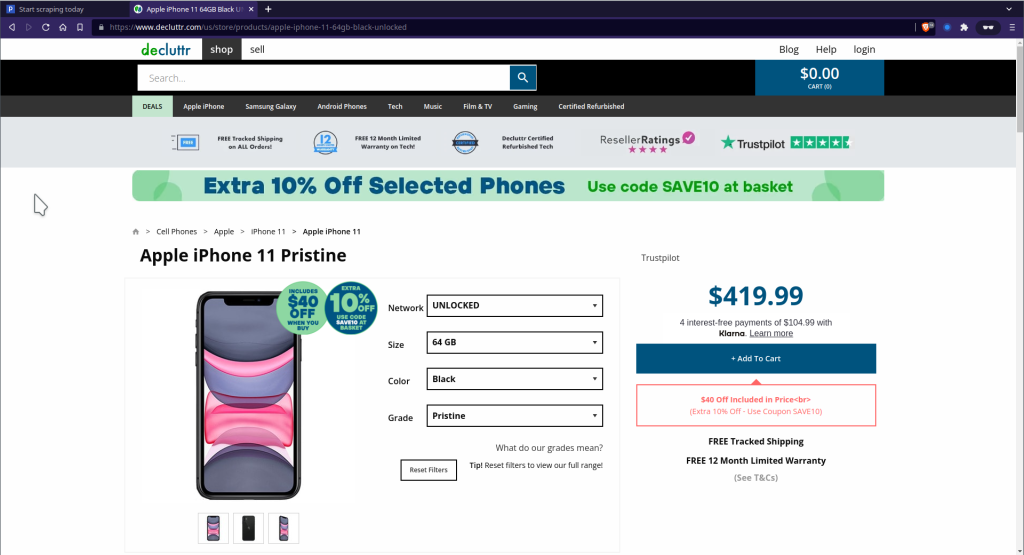
Step 2. Configure Scraper to extract data
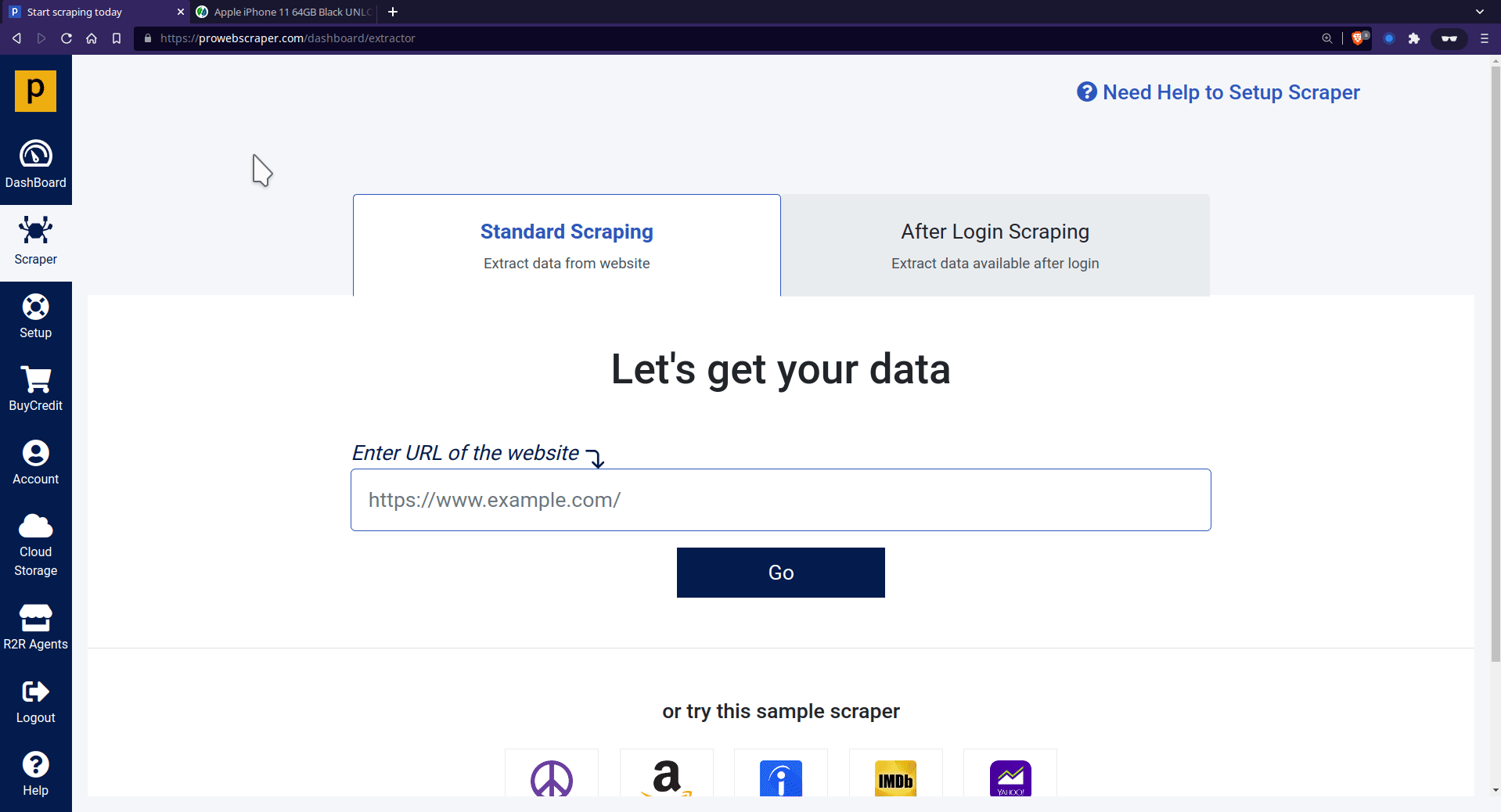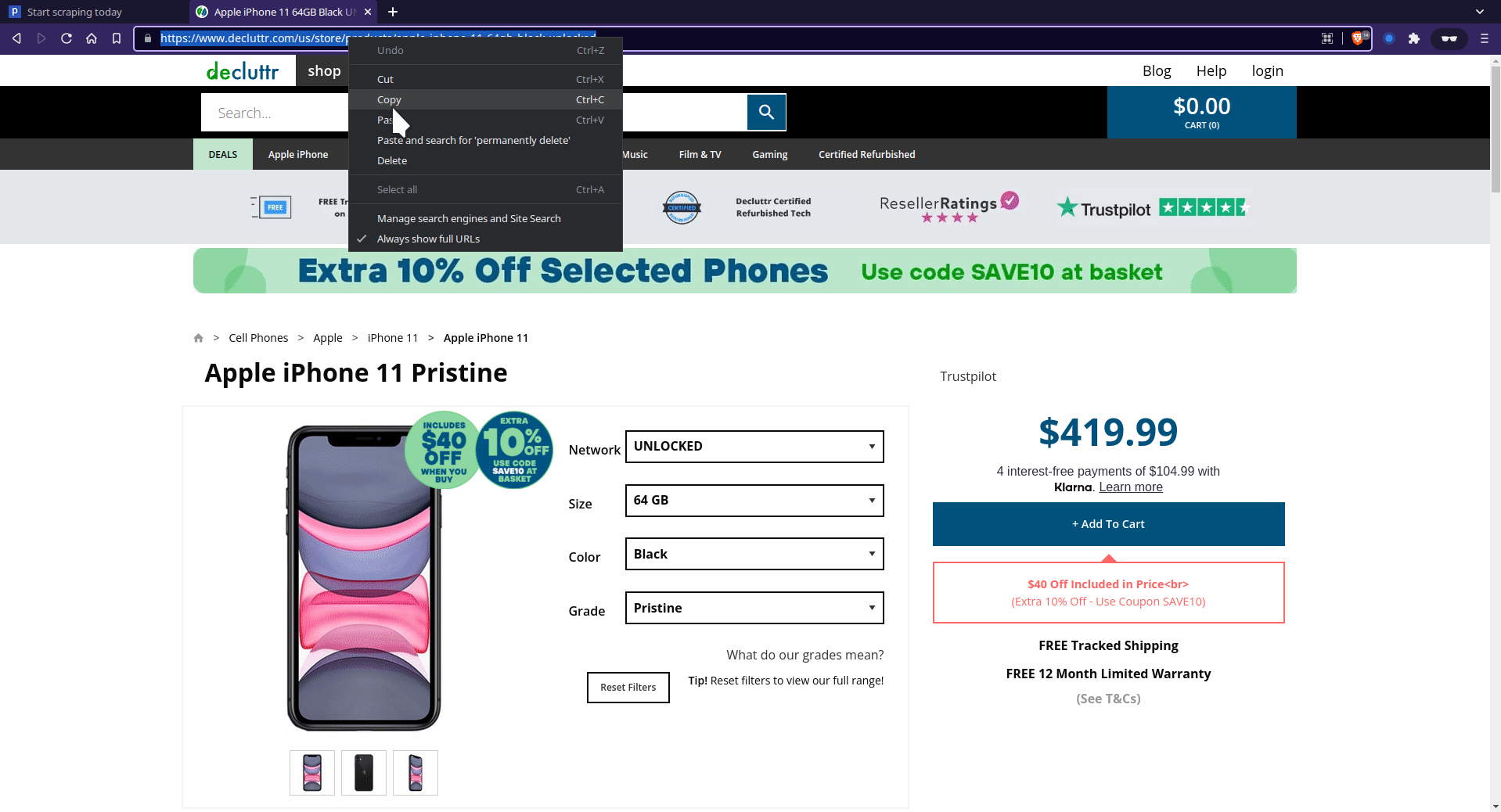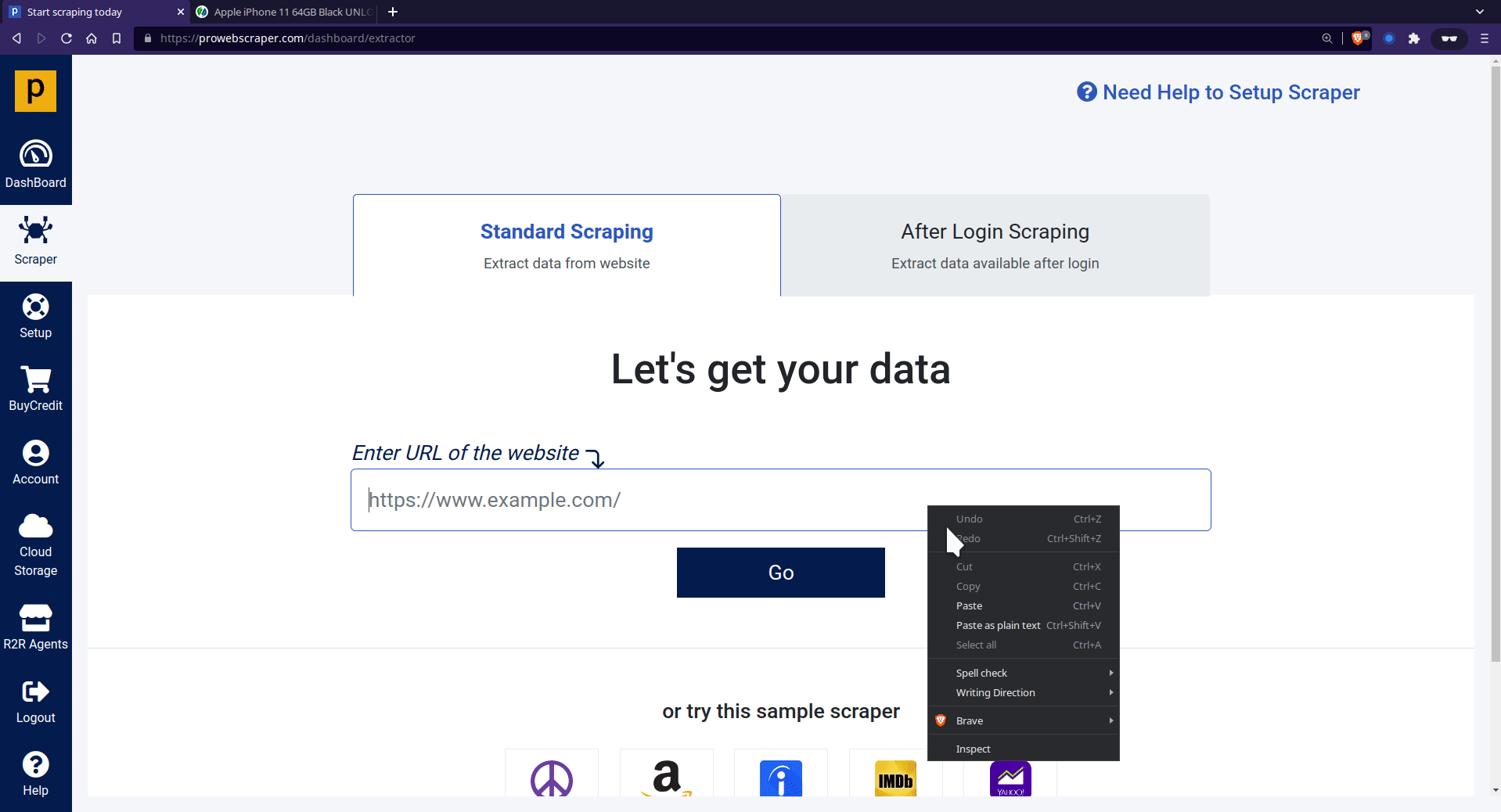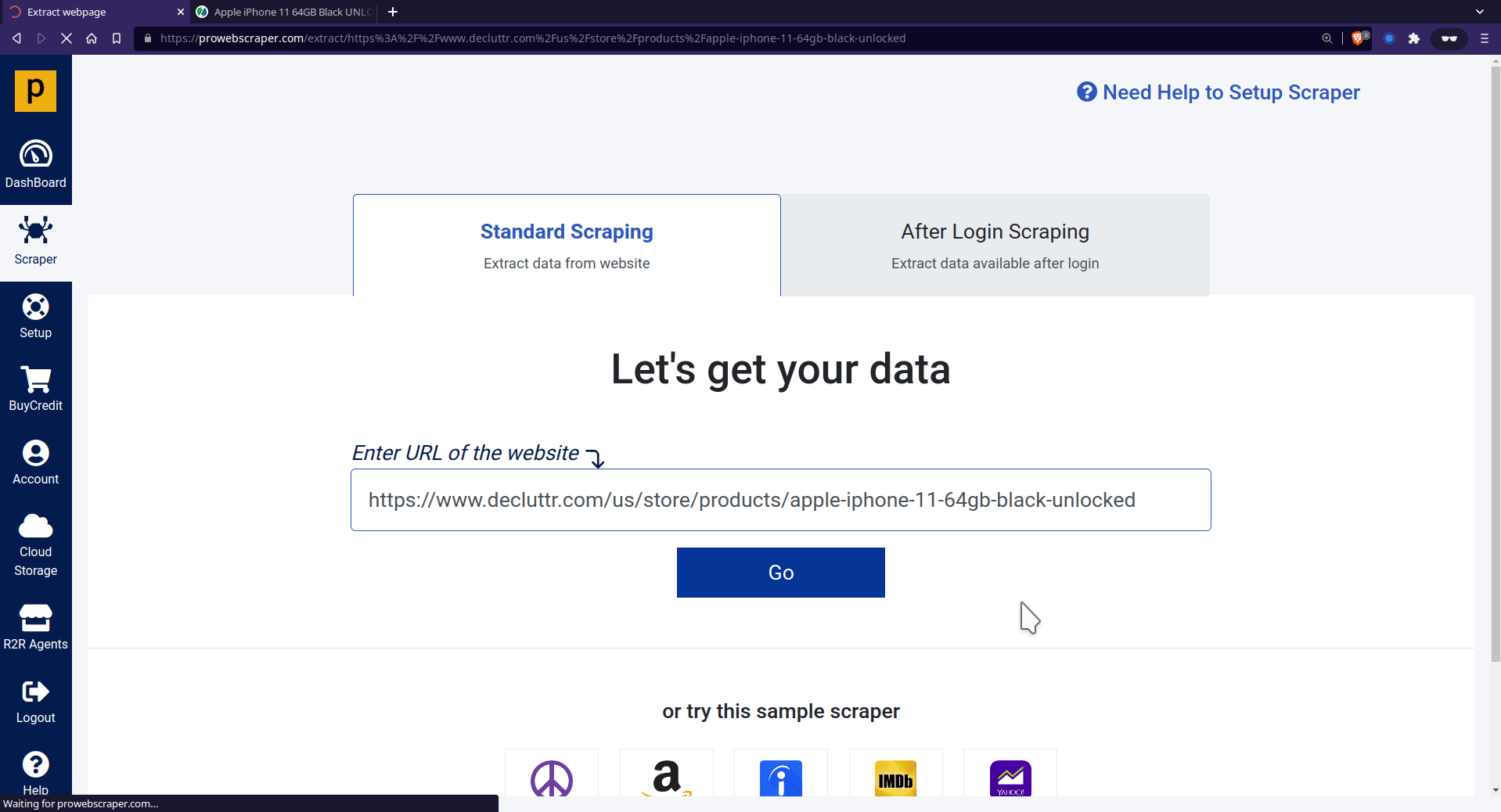
Copy and paste the URL from that page into ProWebScraper, to create a scraper.
Click Go, and ProWebScraper will load the website and let you scrape what data you want.
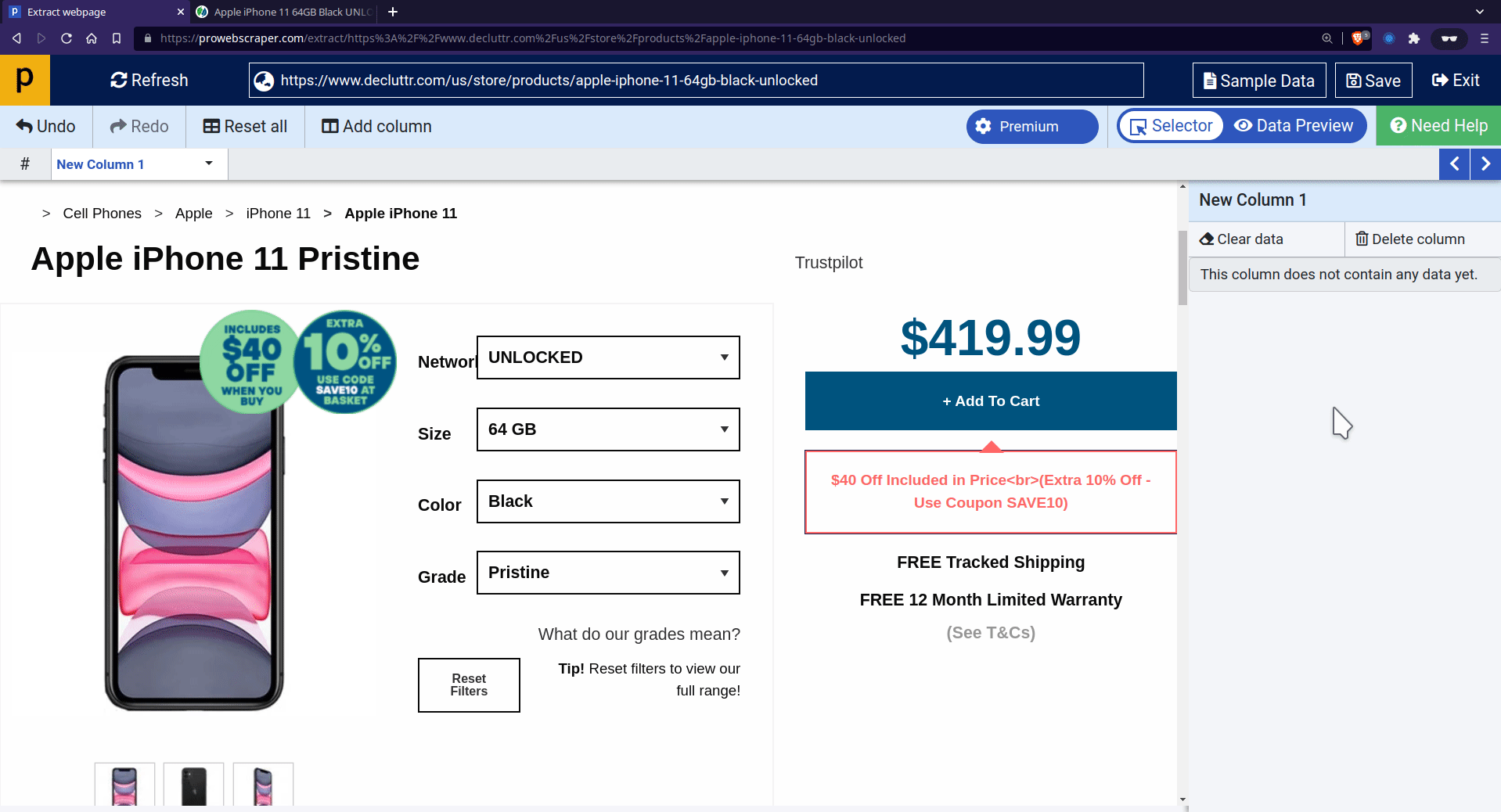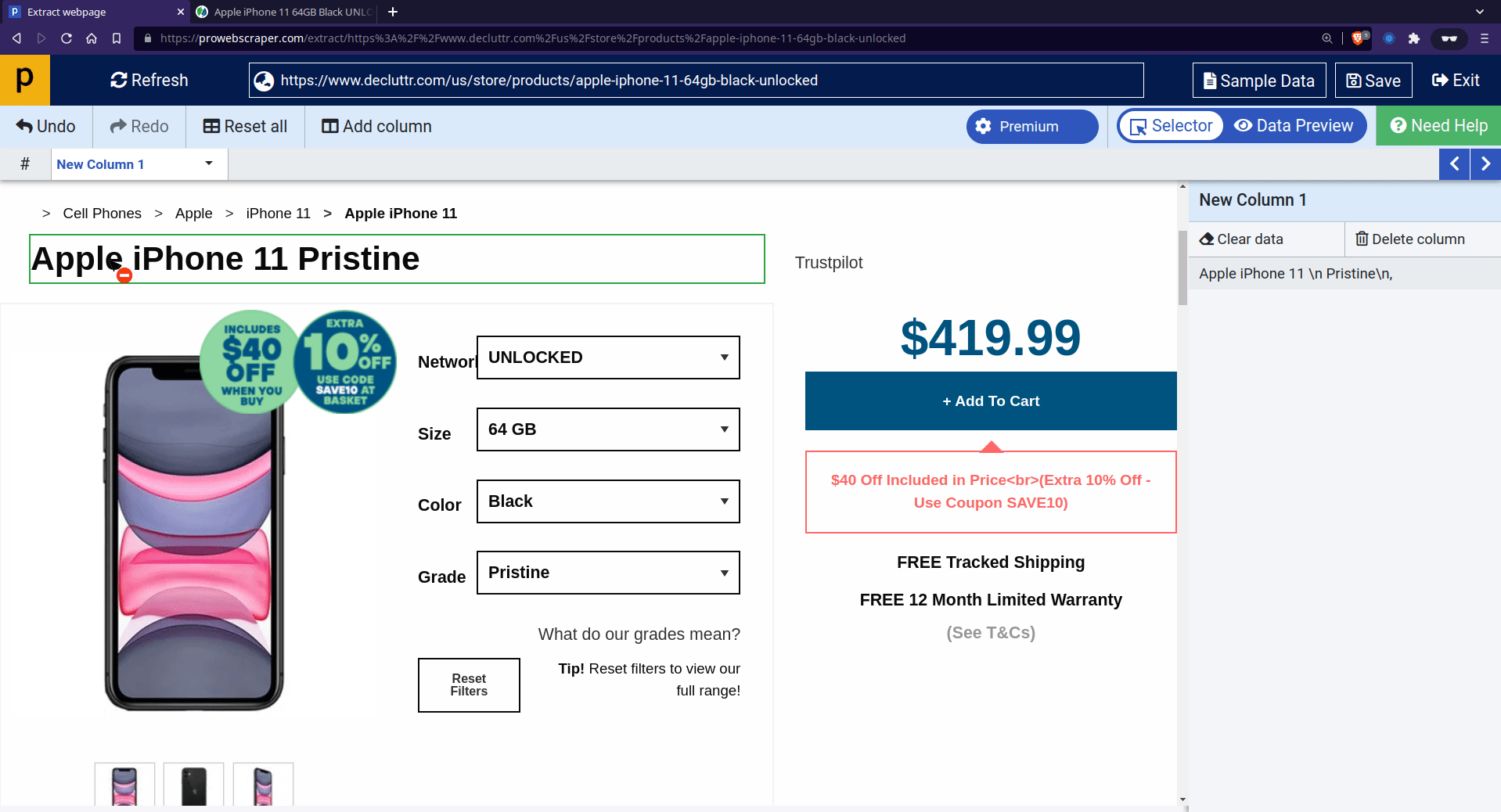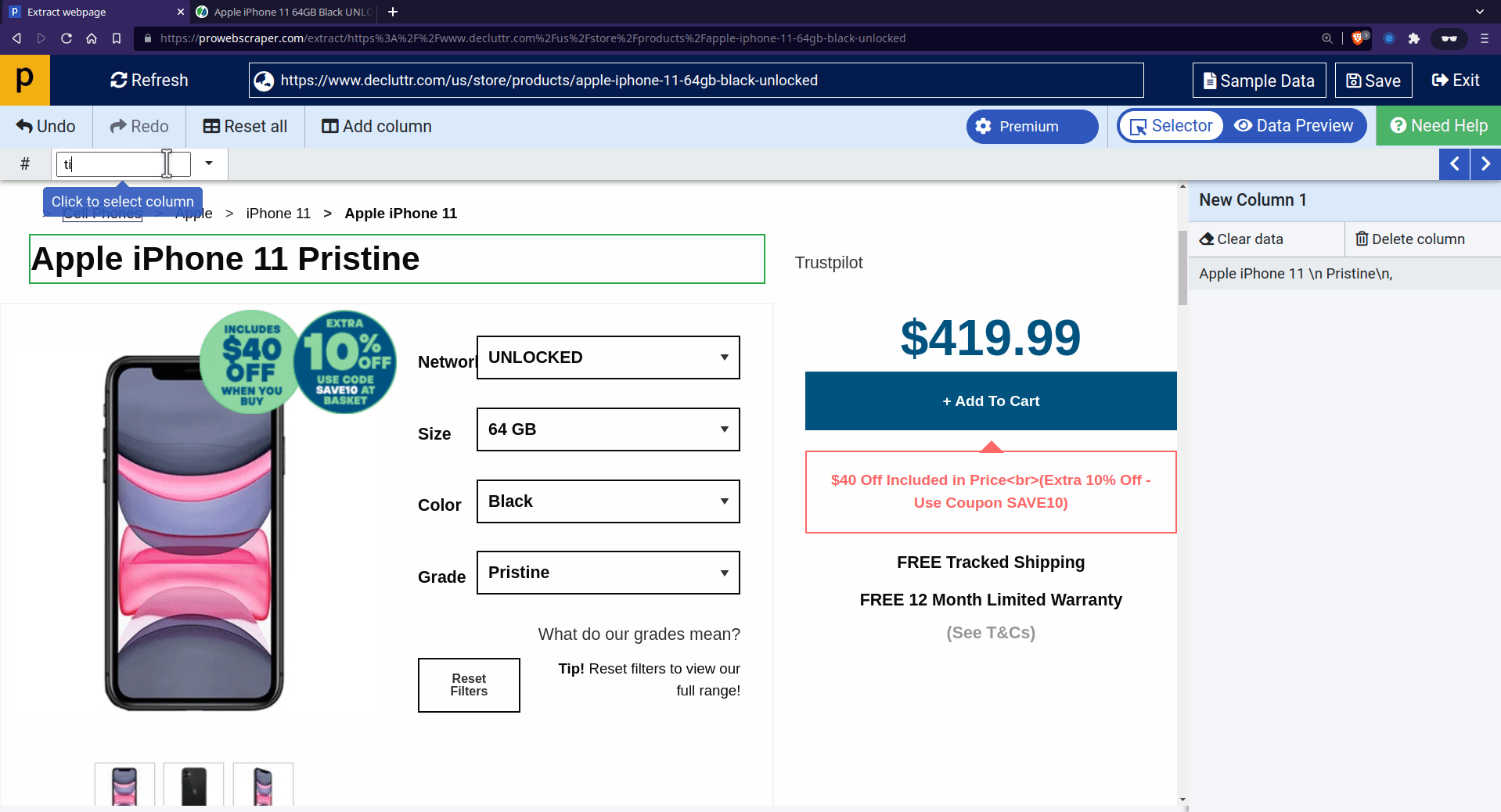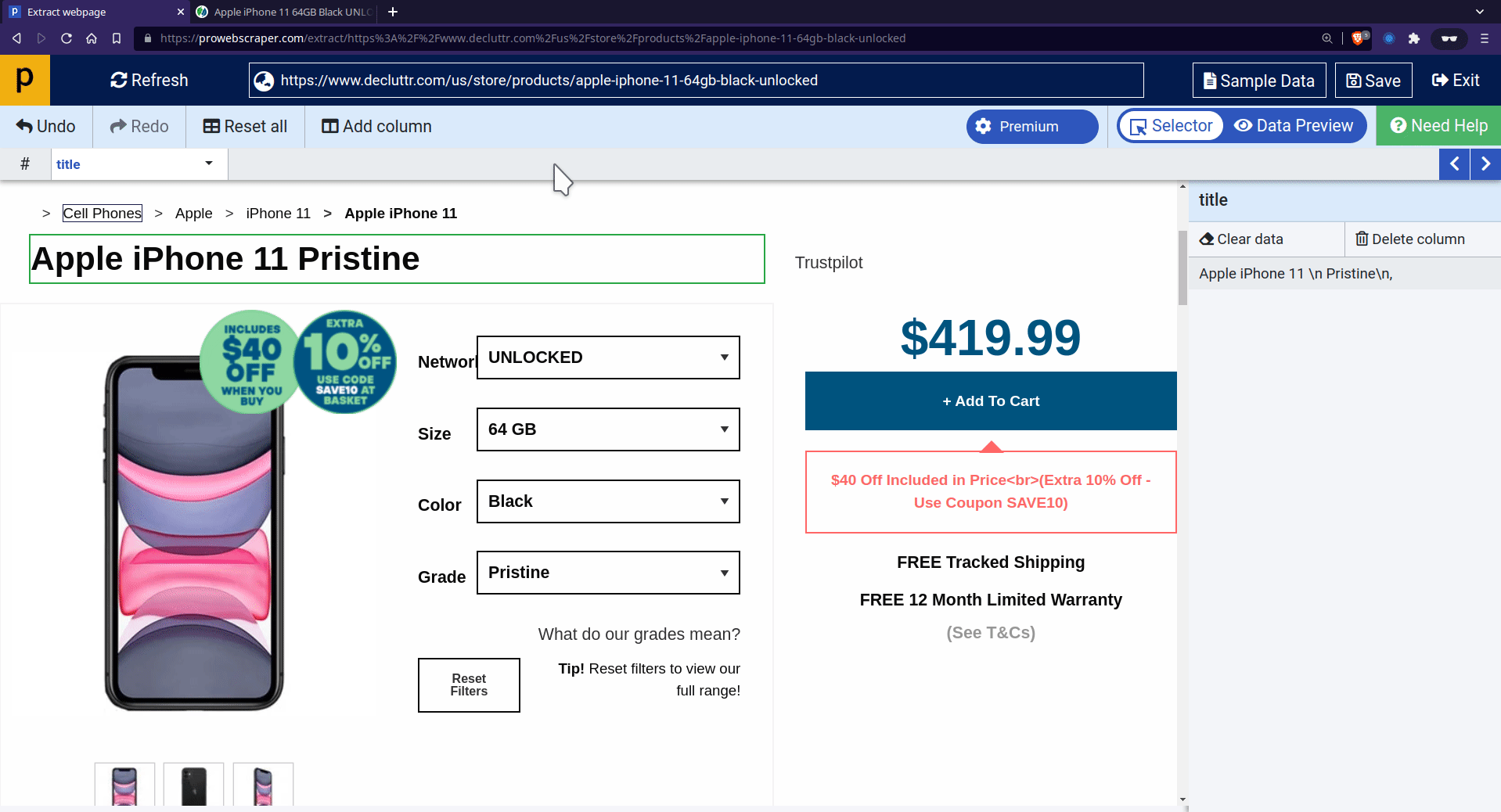
Once it’s done, you can start the data extraction. In this case, we want to extract the Titles, Grade, Image URLs, and prices into columns. We trained the scraper by clicking on the items in each column, which then outlines all items belonging to that column in green.
- To select a title, click on the title, and you may want to name it as well – either double-click on the name or select rename from the columns setting to name this data point.
- To extract more data points (such as Grade, Images, etc.), you need to click on the “Add column” and then click on the page to select that particular data point.
- You can trim the Image URLs to get a full-sized image.
- To do this, go to column setting > set regular expression. Then match “mini” and replace it with “product” and apply it. See the below GIF to have a better idea.

💡 Reference: You can refer to this tutorial to learn more about “Regular Expression.”
In some cases, elements you want to extract from the page are hidden or not selectable in a selector,
At that time, you can use an alternative way: CSS selector or Manual Xpaths to select those elements on the page. For example, we will try to scrape the price with a CSS selector in this case.
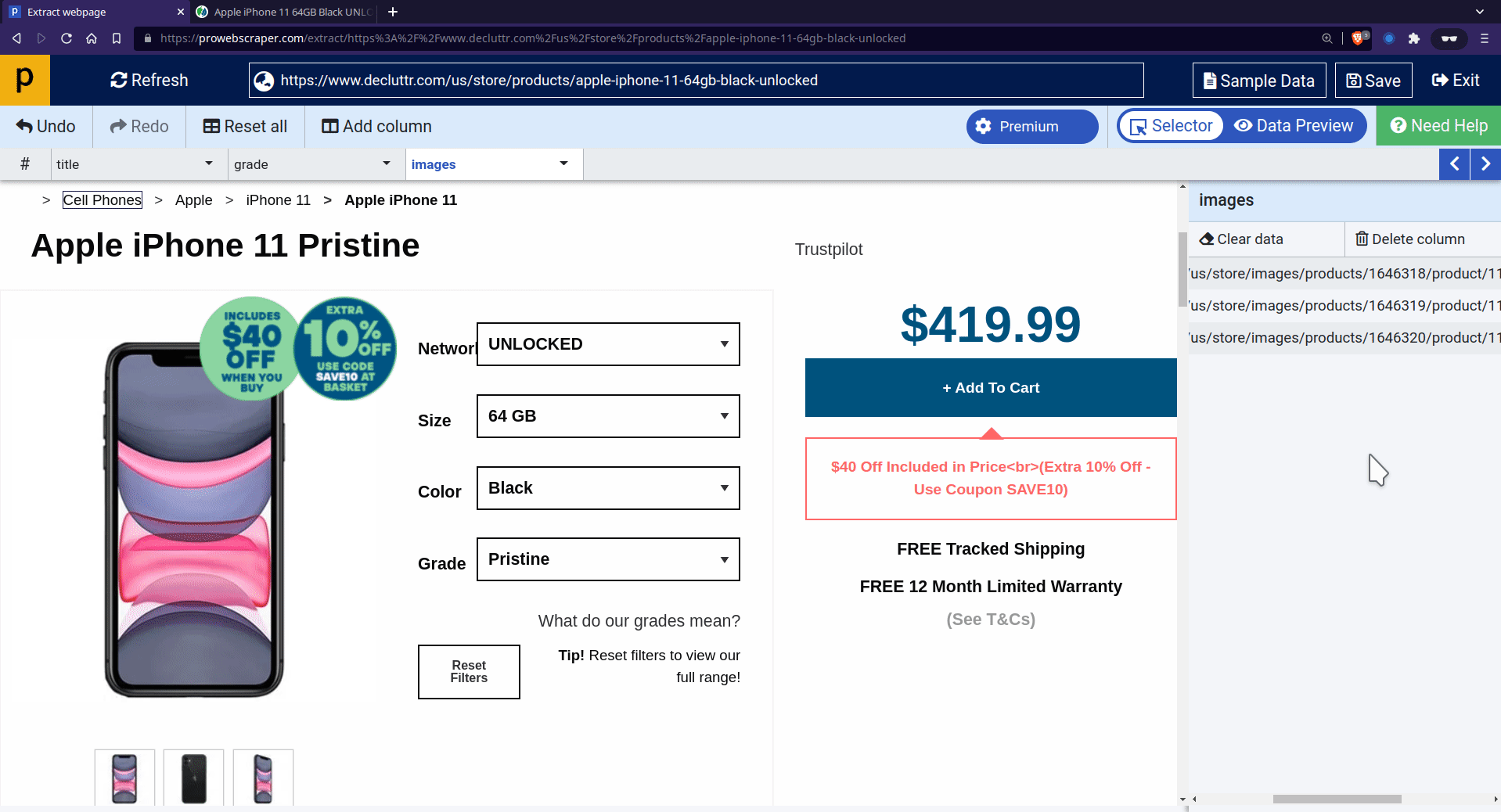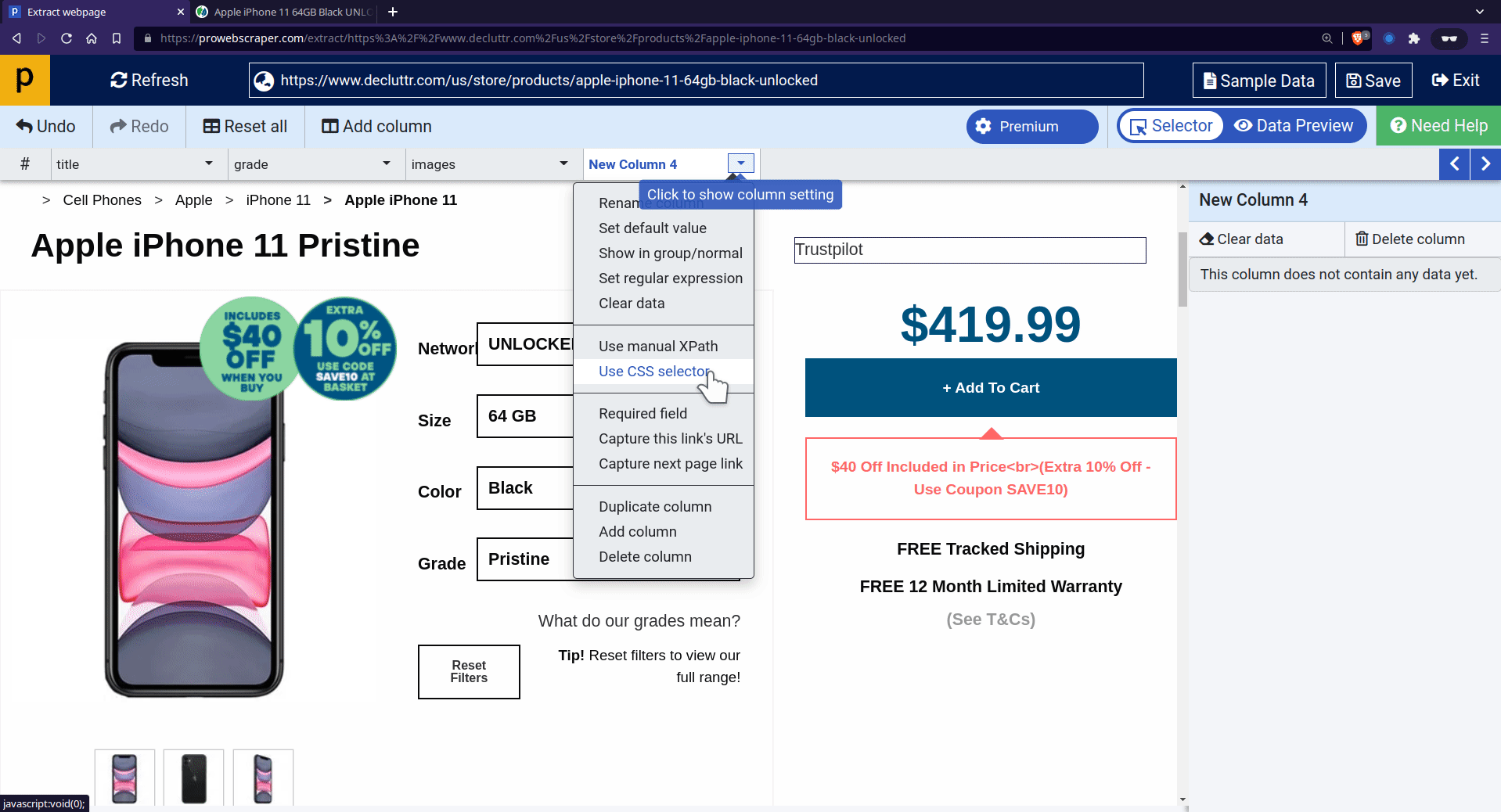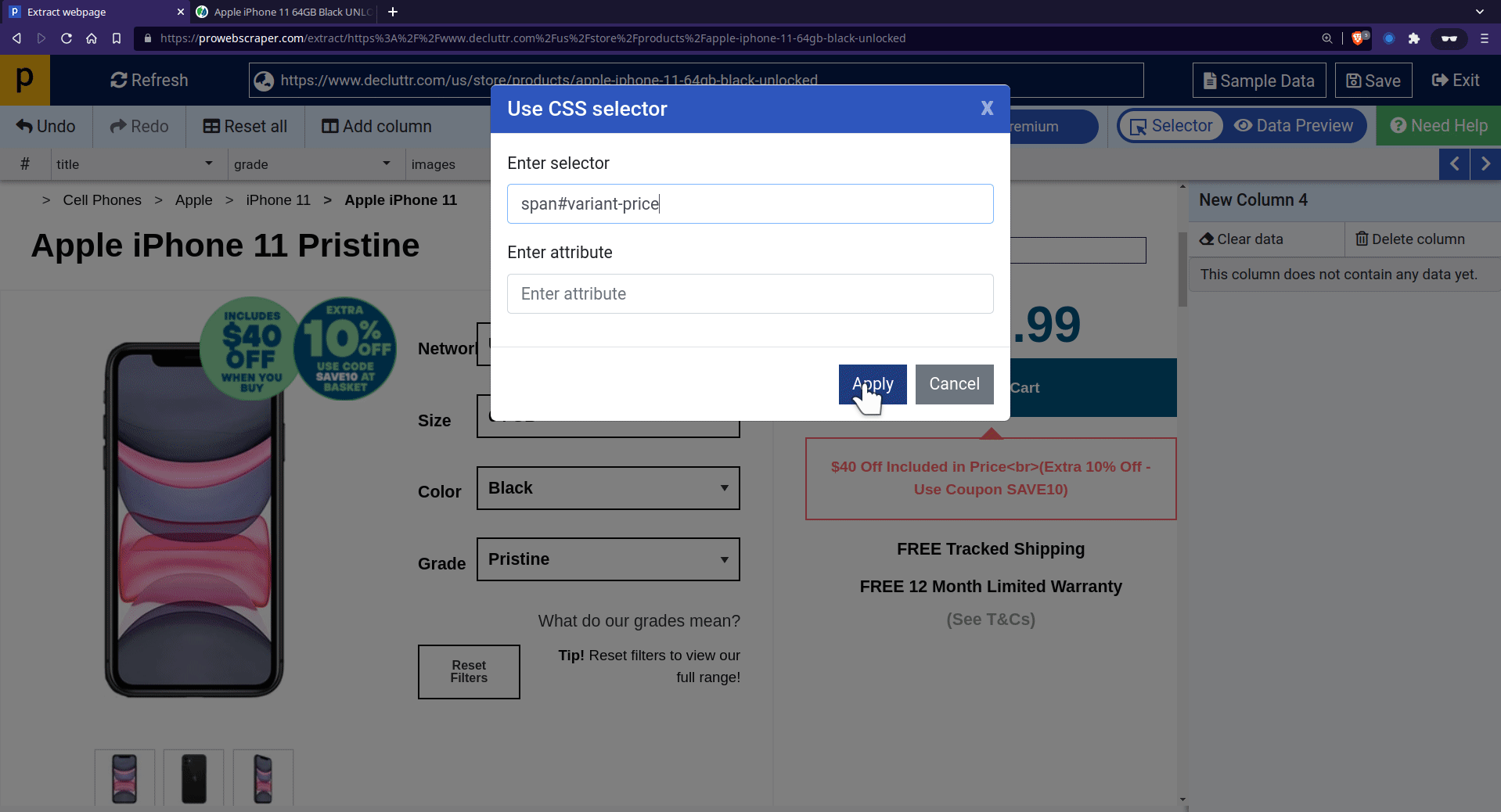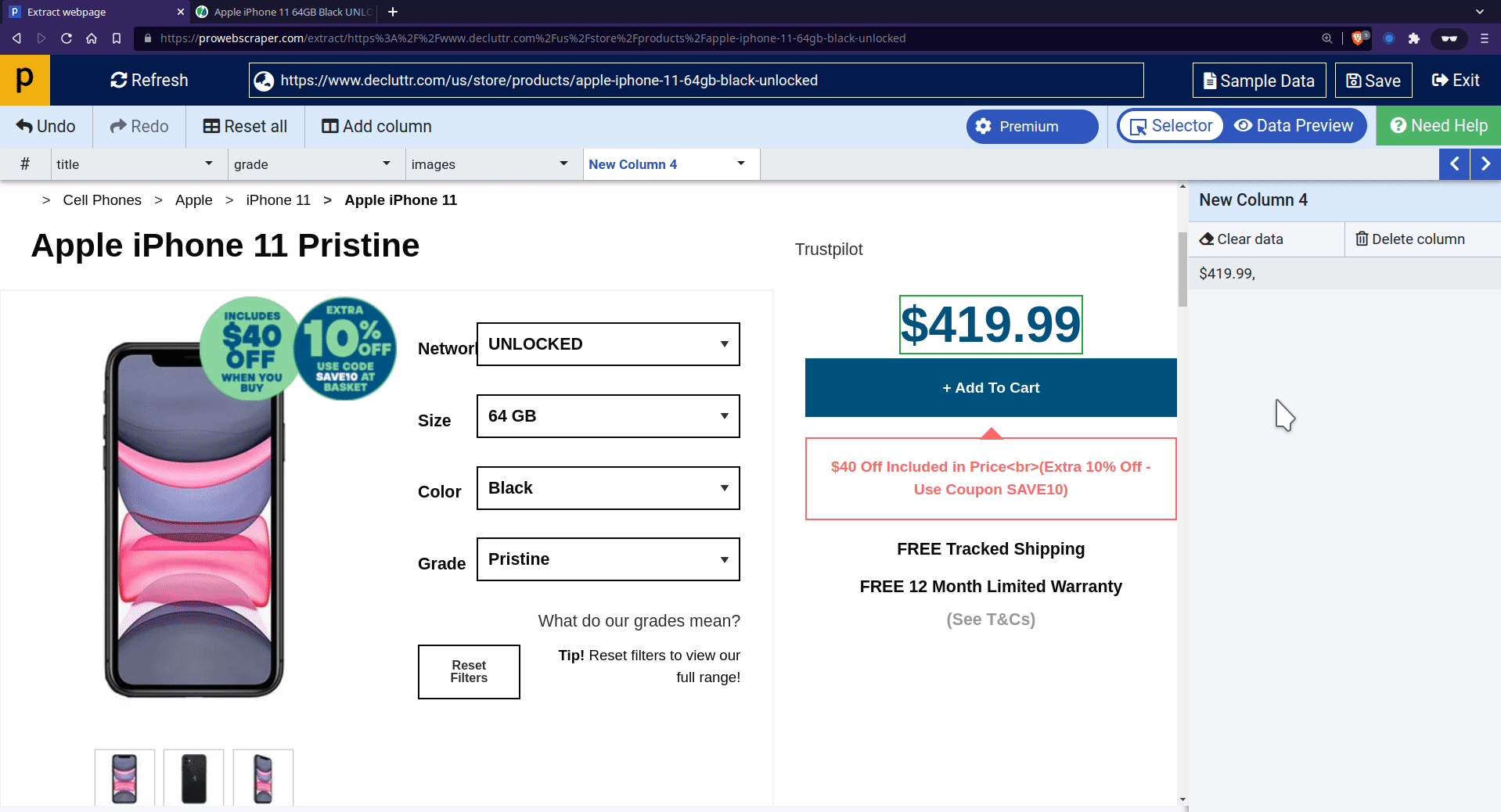
- To apply CSS selector, go to column setting > click on “Use CSS selector”> paste “span#variant-price” into the enter selector field, then apply it.
- You can see that price is selected.
NOTE: Same way you can select color variation and size variation.
Use below CSS selector strings for
Color Variation: “#ddlcolorID > option[selected=“true”]”
Size Variation: “#ddlsizeID > option[selected=“true”]”
💡 Reference: You can refer to this tutorial to learn more about “CSS Selector”.
Step 3. Save And Run Scraper
Once all data points get selected, click on Save to save and run the scraper.
- Once the scraper run is successfully finished, you can see the preview of scraped data.
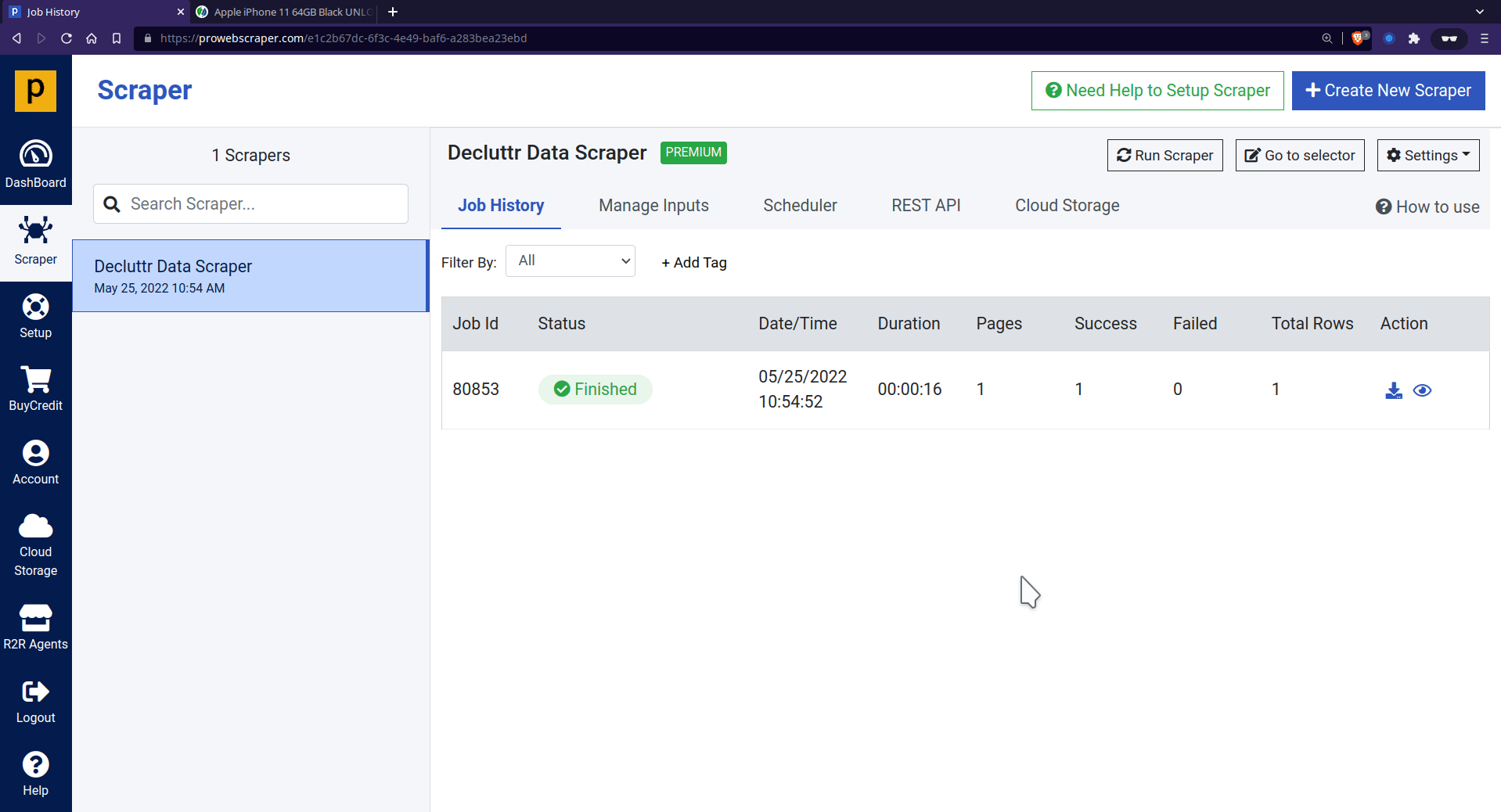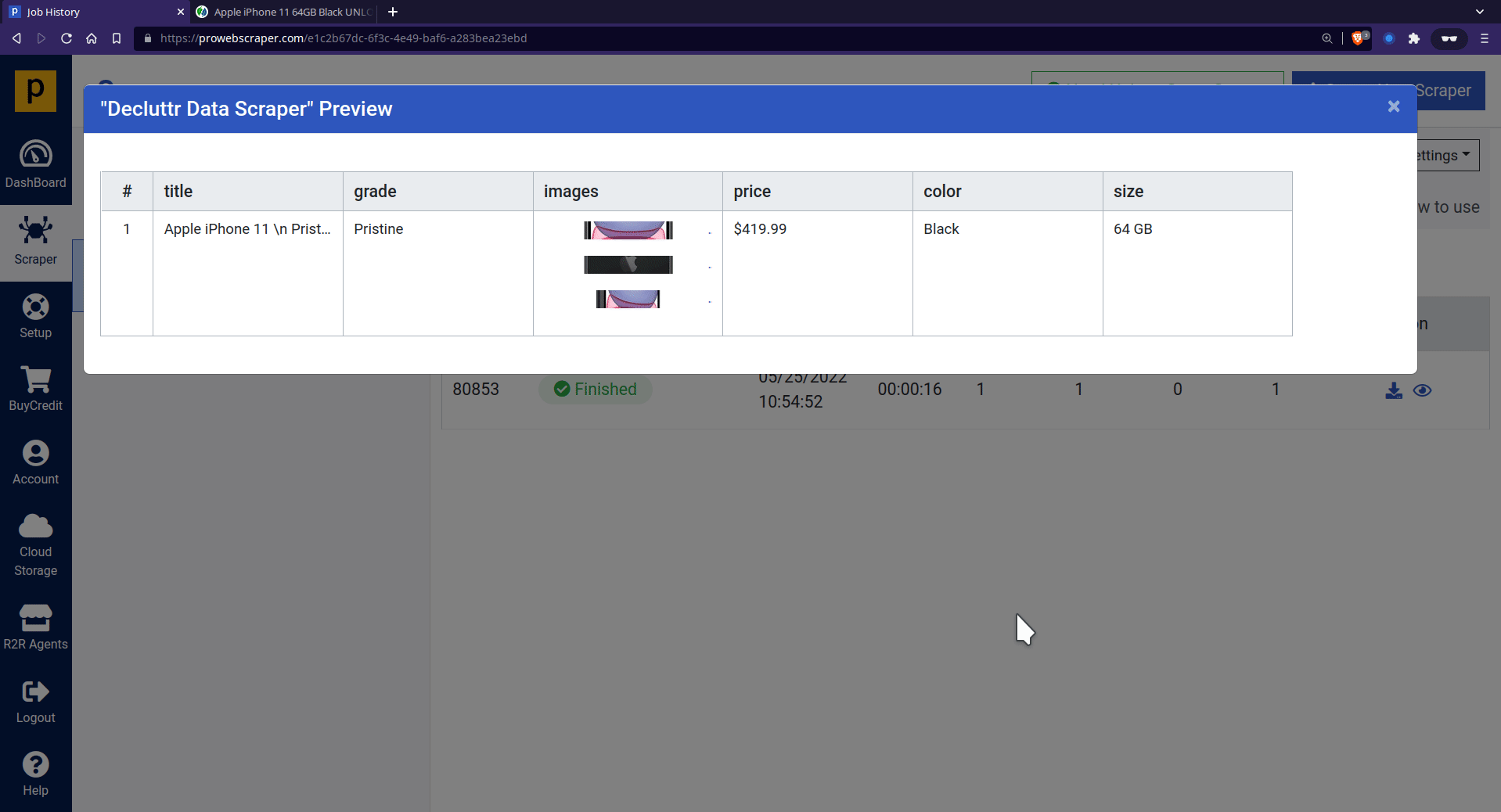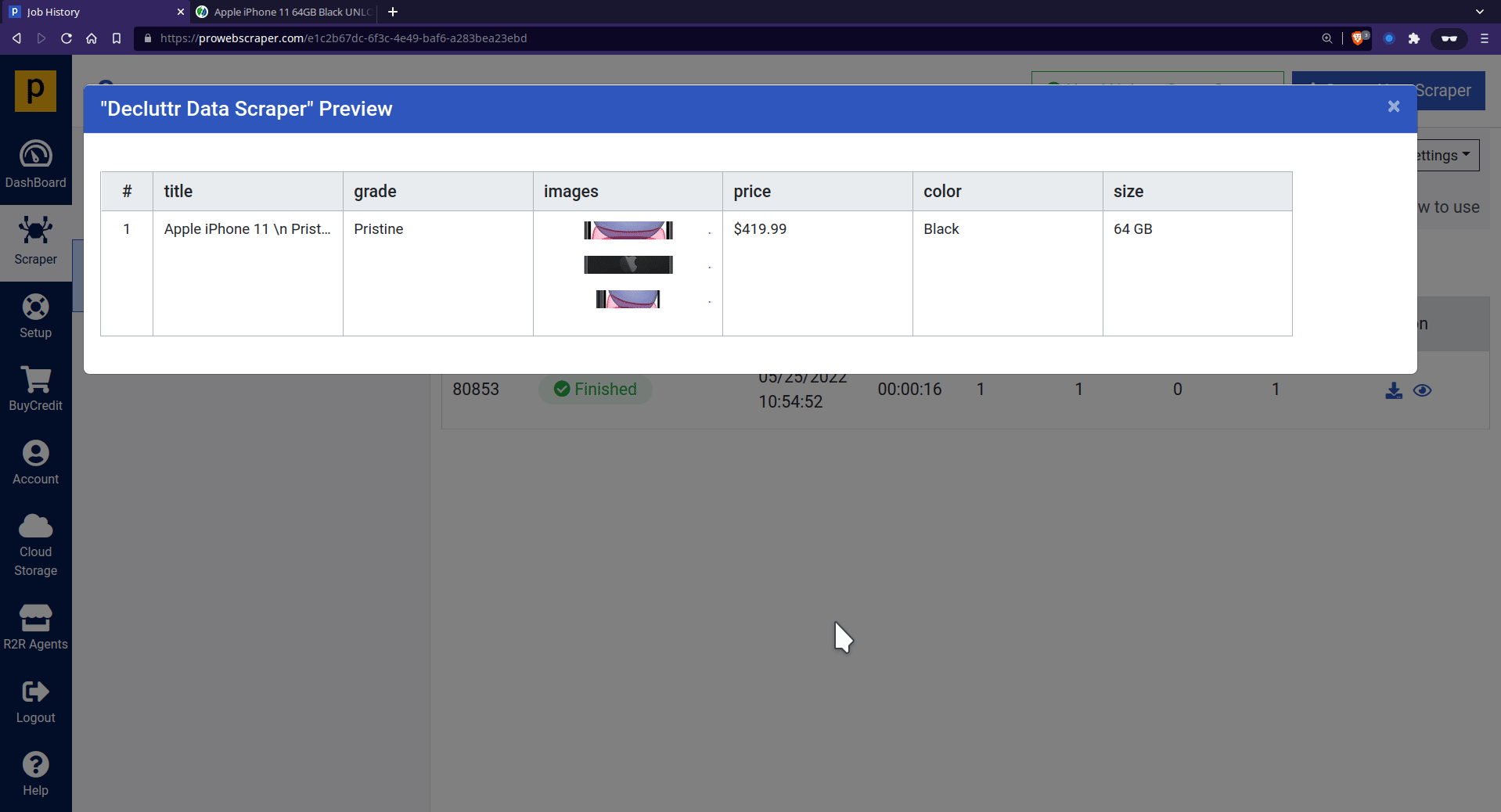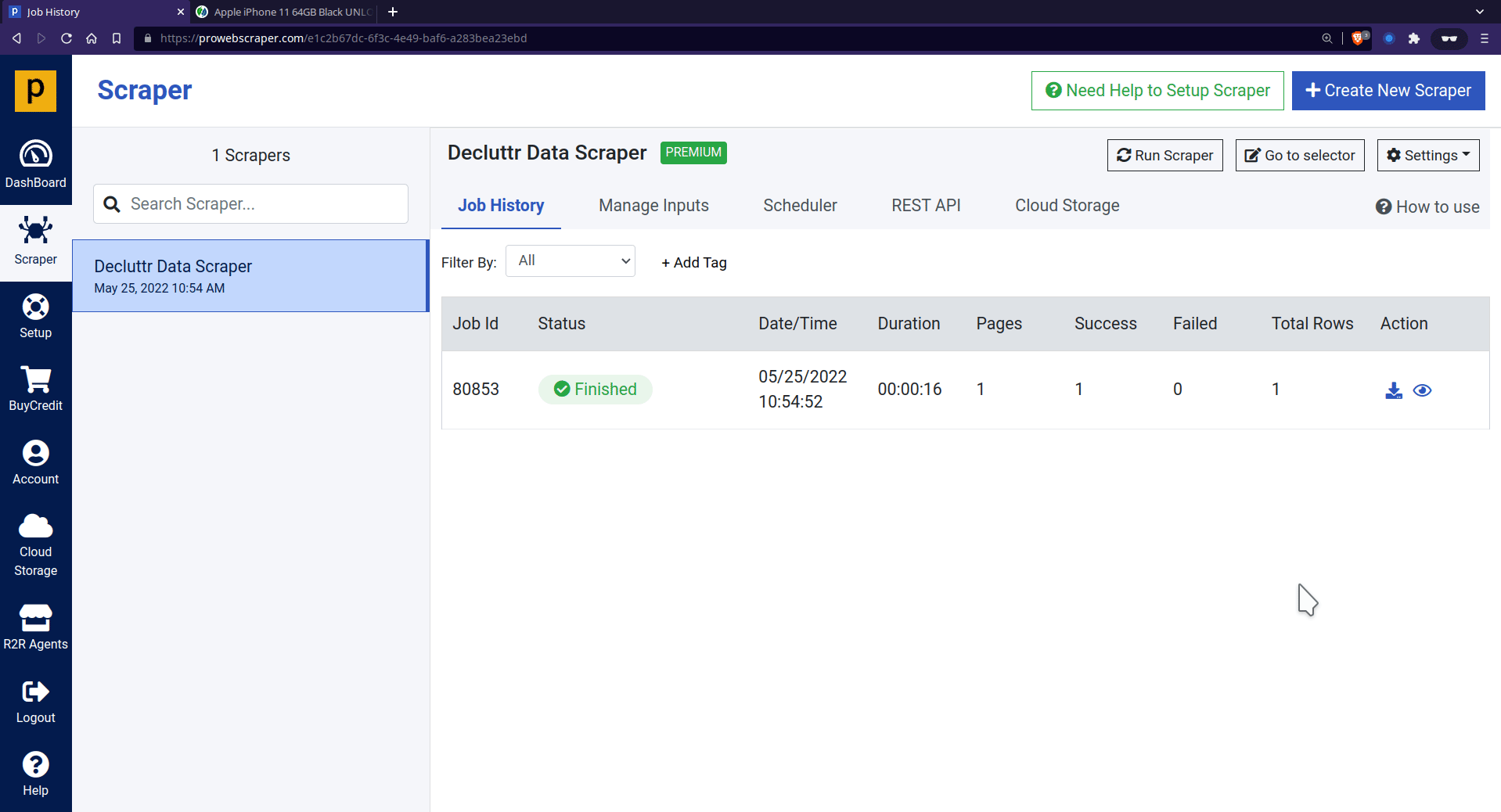
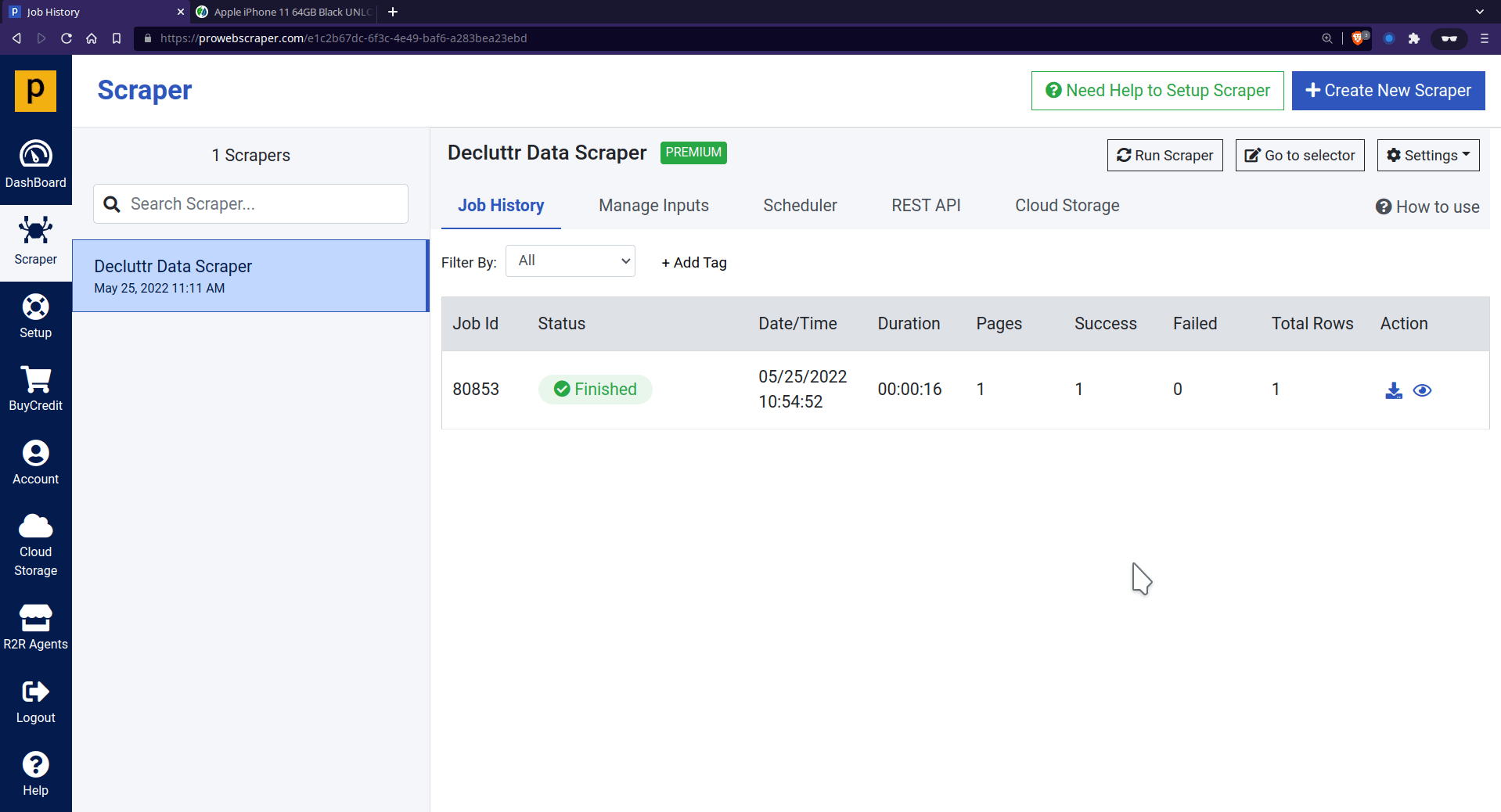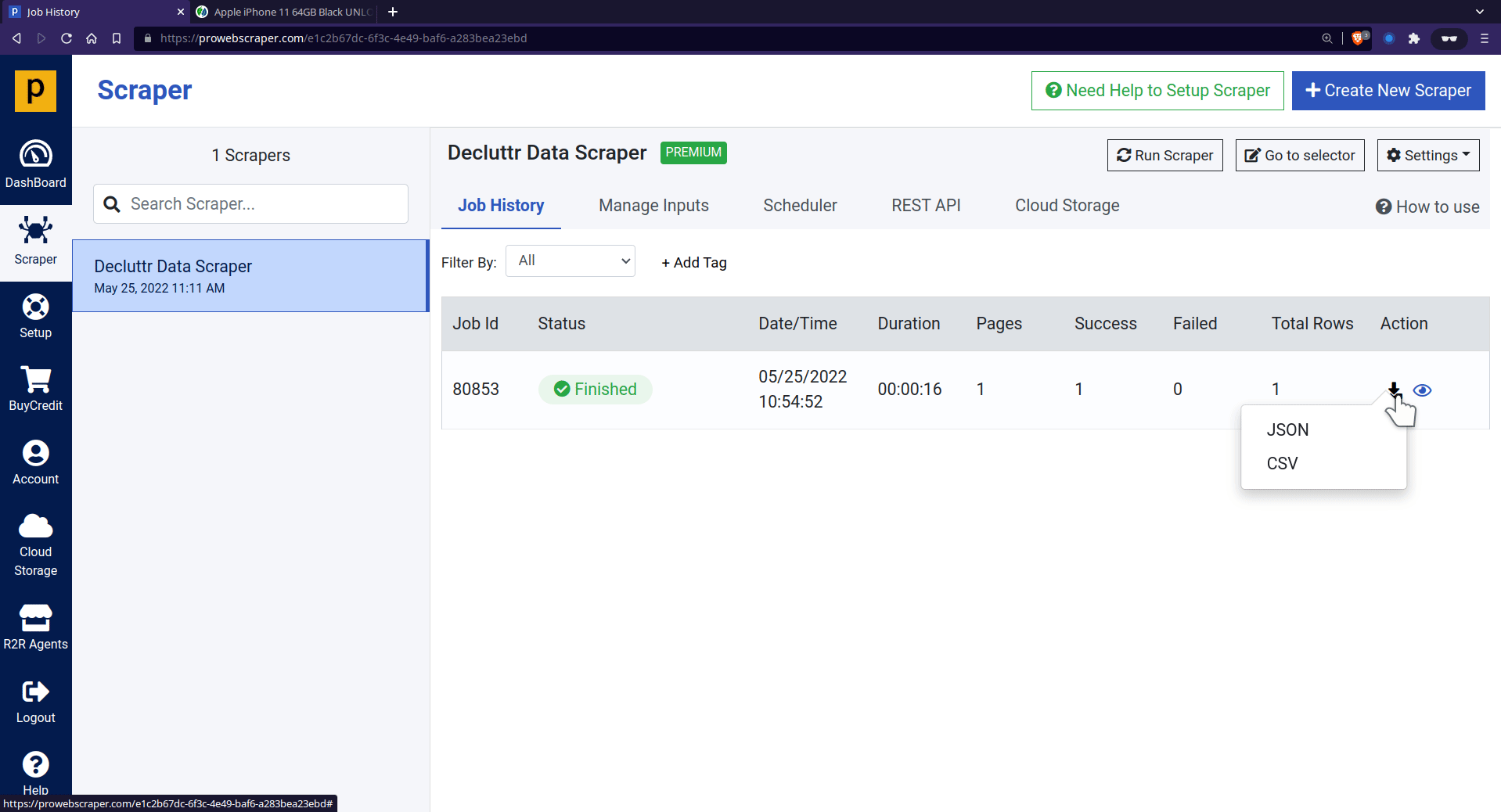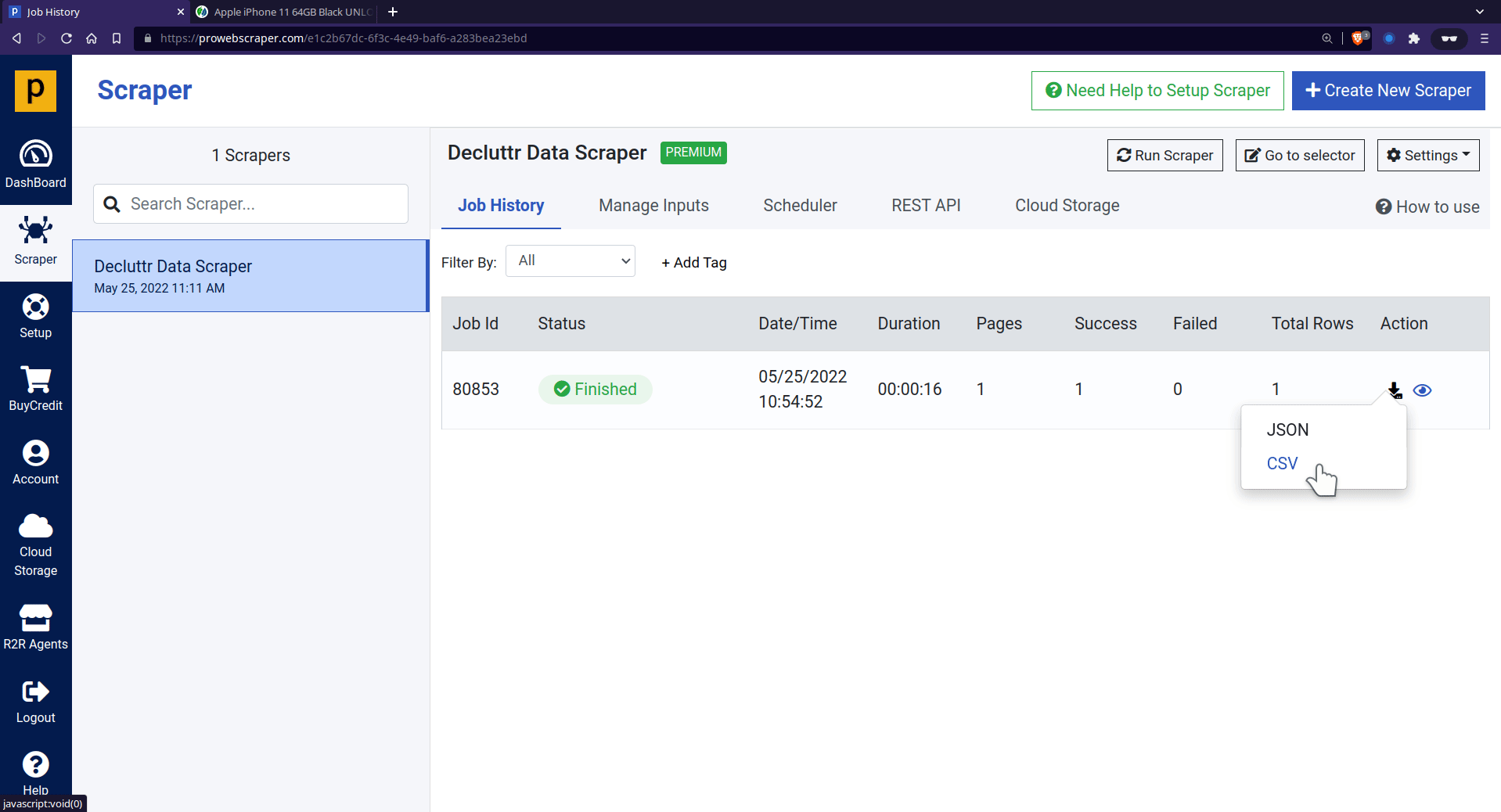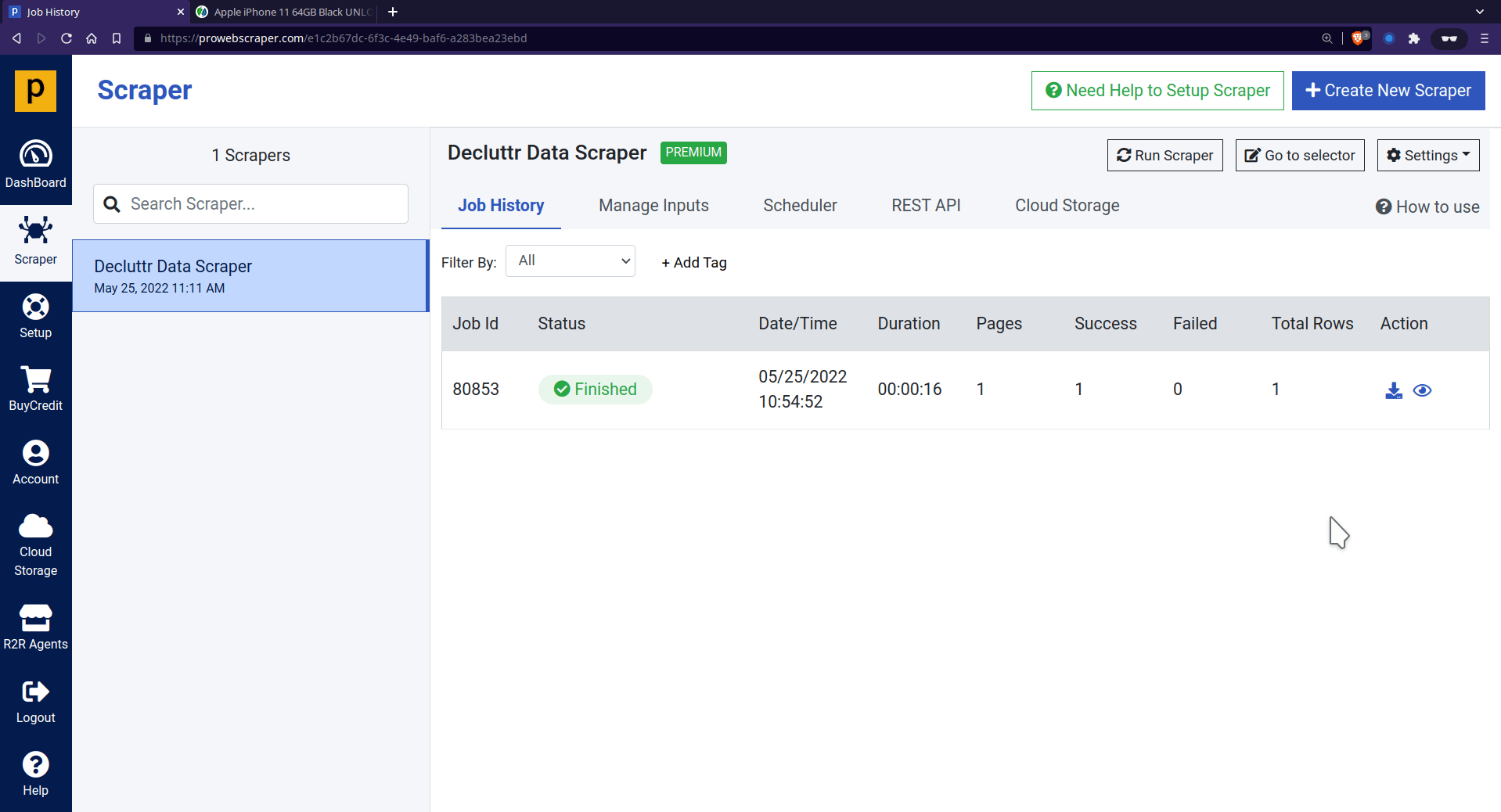
- Now, you can download the data in JSON or CSV format.
Step 4. Bulk Price Scraping
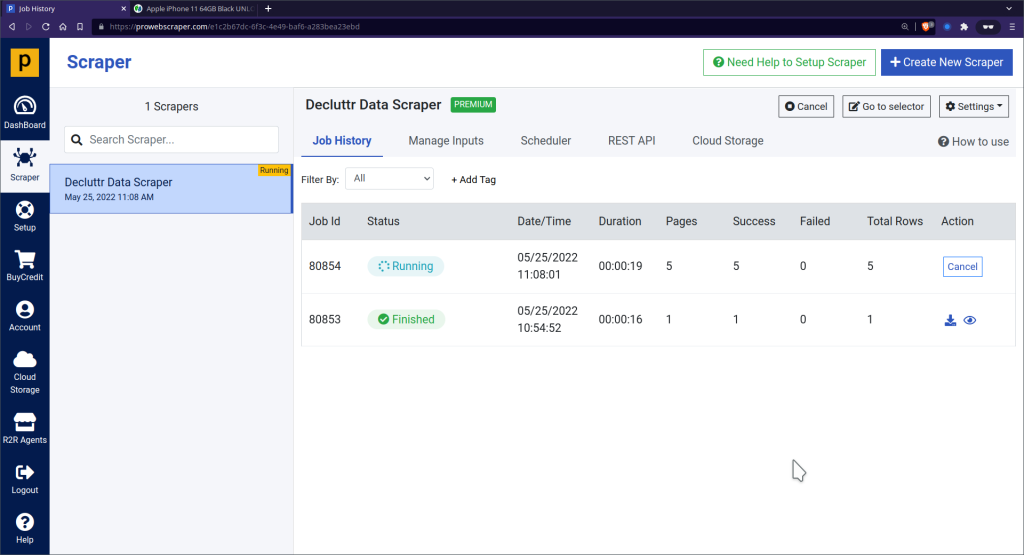
Import BULK URLs to scrape data from more than one variant of iPhone 11.
You can import URLs from CSV or text files. For example, I have saved some URLs in a text file that will be imported into scraper so we can scrape data of all variants.
To import URLs, Goto “Manage Inputs”> “Import URLs,” then browse the file and click “Upload URL list.”
You can see that all URLs are added to the list. Then if you save and run scraper, you can notice that data are scraped from all imported URLs.
Step 5. Download Scraped Prices in JSON or CSV format
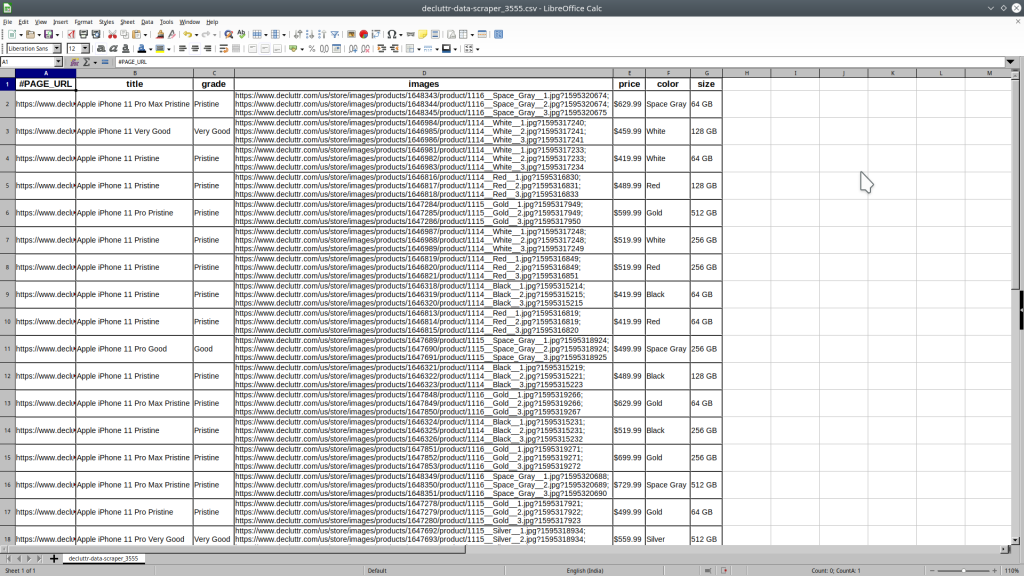
Download all data in CSV file and Data in CSV file preview
- You can see here how scraped data looks like in CSV format
Step 6. Schedule your scraper
- You can schedule your scraper to run regularly to get the latest information from a webpage.
- To schedule a scraper,
- Go to the scraper’s “Scheduler” tab.
- Select the following options: hourly, daily, weekly, monthly, or advanced.
- Select the advanced option to customize a schedule using cronjob GUI.
- For example, if you need the latest information daily, select the frequency: Daily. It will run your extractor every day at a specific time of the day.
💡 Reference: You can refer to this tutorial to learn more about “Scheduler.”
Conclusion
Whether you want to monitor your competitor’s price or scrape prices for MAP compliance, you’ll need a tool that doesn’t get blocked. Additionally, you’ll need a tool that gives you price data consistently.
With highly scalable infrastructure and pools of proxies, ProWebScraper has the capabilities to fulfill your needs. Also, ProWebScraper lets you scrape 100 pages for free! So, without wasting time, let’s start using this tool. For any more queries, you can contact the sales team.