Want to scrape bulk data without getting blocked?
Want to scrape bulk data without getting blocked?

When you happen to meet a stranger more than usual, don’t you doubt that it may not be happening by chance? You then make up your mind to be cautious, right?
Similarly, when you crawl a website faster than humans, you give the target website a room full of suspicion to hint that it is a bot. A very common example could be you using a bot to scrape images or links from the same IP address and that too for a long time, there are high chances that the website will block you.
Once the website owner doubts of you not being a human, they will get double sure to allow browsing. If the website raises a point of suspicion, it will do these with you:
If by any chance you happen to get blocked, you will not be able to access all or a part of the site’s content.

Websites can easily spot any unusual activity and block your web scraper. as they are enabled with anti-scraping software. In common, these are the ways through which a website can detect scraping:
Every time you click on a website, your IP address is stored in the server log file. After spotting repeated entries, your web scraper will be blocked.
Apart from noting the internet protocol address, if the website finds that a web form is filled faster than a human, they might suspect it to be a web scraper.
The website you are trying to scrape checks for the user-agent. The browser in common generates a user-agent that tells the website being scraped about the user’s environment. But if the scraping request you place misses a user-agent, the source website will easily find that it could be a bot.
Using Honeypots is a deceptive methodology to prevent web scraping. It is a way to find out about the goal of the scraping site. Using the honeypots, websites can keep web scrapers away and rather waste a lot of their time. There are different types of honeypots, like honey systems (that imitate operating systems and services), honey service (imitates software or protocol functions), and honey tokens (imitates data).
The source website can show a CAPTCHA for subsequent requests when you are trying to look at an excessive number of pages or trying to perform more than usual searches. They would set a rate limit and allow users to browse the website for a certain time only. For example, your competitor allows your web scraper stool to fetch only a few pieces of information per second if you try to fetch the information from the same IP address.
Any website can prevent intervention from the cloud web-hosting service. Some scrapers use web hosting from Amazon or Google App Engines. The requests by the users originate from the IP addresses which are used by the cloud hosting services.
In some other cases, a website will stop you from fetching data if you use an IP address used by proxy or VPN providers.
When a website wants to stop you from taking away the details, it will serve you the content as a text image. It will make the job of scraping challenging.
The website owners can restrict the information like articles/blogs and make them accessible only by searching for them via the on-site search.
If you send a scraping request without a user-agent header, the website will first show you a captcha. In other cases, it will block or limit the access or serve fake data and stop you from data scraping.
A scraper may use some part of your HTML code and fetch information written there as it is. But if you change the HTML and the structure of the page frequently, the scraper will fail to fetch any substantial information. You must frequently change the id and classes of elements in your HTML. Also, you must remove or add extra mark-up in the HTML randomly as this will make it difficult to scrape your HTML code.

Here are 21 actionable and essential tips to crawl a website without getting blocked:
A simple but dynamic tip to crawl a website is by rotating an IP address. By now you know that sending the request to crawl from the same IP address can put you in a fix.
The target website will soon identify you as a bot. Whereas, if you rotate your IP address it makes it look like there are different numbers of internet users.
Deploy the correct user agent when you plan to scrape a target website without getting blocked. The user agent string that you send through your scraping request allows the destination server to spot the operating system, browser, and the type of device in use.
When scraping, you must use a real user agent that belongs to a major browser otherwise your request to scrape can be blocked. Examples include:
→ Mozilla Firefox: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:53.0) Gecko/20100101 Firefox/53.0
List of user agents: https://deviceatlas.com/blog/list-of-user-agent-strings
TCP stands for Transmission Control Protocol that is a standard to define in what way to establish and maintain a network conversation. It helps application programs to exchange data. TCP is what makes the internet strong. Most of the target websites you want to scrape use TCP and IP fingerprinting.
TCP fingerprinting relies on the IPv4, IPv6 and TCP headers to identify the OS and software sending a request. This implies that if you are sending inconsistent values in TCP packets, you can easily get caught. It allows them to detect the bots as soon as they arrive to scrape.
If you want to pass this, make sure the parameters of TCP are set and kept consistent. Set headers in the right formatted way, so that the TCP packets make sense for the operating system it claims to have running.This is important because there are chances that TCP leaves various parameters while scraping.
The target website can use the technique of browser fingerprinting. It in simple words is the art to collect all the information about the user and monitor their activities to create a fingerprint.
The website usually runs a script in your browser’s background to find out the operating system you use, device specification, and browser settings. It can also help them establish the time zone, language, user-agents of your request. They then spin all the information to create a ‘browse fingerprint’. After the fingerprint is ready, you may try to change the user-agent, use an incognito window, clear the browser’s history or cookies, you will not be allowed to scrape.
However, to prevent this from happening to you use a ChromeDriver approach which involves using WebDriver protocols and implementation of Chrome. This is a way to programmatically get the data you want. But you may need to download executables that use Chrome’s libraries.
Honey pot trap is an anti-scraping link that is set by website owners to detect web crawlers. It is the easiest way to spot scraping activity. In order to crawl a website without getting blocked, you need to check whether the target website page code has “display:none” or “visibility:hidden”. Honey Pot Traps are installed and added to CSS or JavaScript.
Before scraping, you need to check each page for these hidden CSS properties set. Avoid following the links else the website will identify that you are a bot and not a human. And if the target website detects something fishy, it starts to create a fingerprint of the patterns you browse and block the web scraper immediately.
You must have encountered a CAPTCHA verification when trying to find information over the internet. It is a common practice that the websites use to confirm that a human is behind the computer searching for the information. Often there are different types of captchas that are used that may include identifying objects in the picture, math problems, or identifying words in the picture.
You can use CAPTCHA solving service to give blocking a pass. The service provides hired human workers as CAPTCHA solvers who are constantly available online. As soon as you receive the request, you can send it to these human workers, who then immediately solves the test and send it back. The method uses OCR technology to solve the CAPTCHA.
For convenient scraping, the easiest thing you can do is to reduce the scraping speed. Slow it down by adding random breaks in two requests you place. When you reduce the number of requests, the scraper will be faster.
One common way to reduce requests is that you increase the number of results per page. Another way to reduce the number of requests is to apply filters before scraping and use a general spider and not a Crawl Spider.
When you crawl a website, the load on the server that hosts the website increases. The crawlers are known to travel the web pages at a faster rate than any human user. So it is better that you crawl a target website during off-peak hours.
If you choose to move through the web pages during the high load time, it impacts the user experience in common. This can also hint at the target web page that is being browsed by a scraper.
A target website you want to scrape is capable of detecting fonts, browser cookies, extensions, and javascript and analyze whether or not it is a real user on their page. If you want to scrape a website, prefer to use a headless browser.
Headless browsers provide identical control of the web page as would the popular web browser does. Using some tools like Selenium and Puppeteer allows the user to write a program that would control a real web browser the same a real user would do. This scraping will help only when you are not using it for large websites.
Headless browsing is faster and automates the process. It is the same as a real browser without user interface, saves loading time, and is difficult to detect as a bot.
Often images are heavy files that are protected by strict copyrights. The size of the image files is higher which will take an additional bandwidth to scrape the data. It will occupy a lot of storage space and that is not it because you might end up violating someone else’s rights.
Scraping the images involves a lot of complexity since these are heavy files and it reduces the speed of the scraper. Hence, you should avoid doing that or use a scraping procedure that is written and employed.
If something is close to impossible is scraping data that is written in JavaScript. If you are trying to scrape such data you may also face issues like memory leaks or complete crashes at certain times. Ultimately, getting the data from javascript will be a difficult task and you might end up getting blocked. It will be just fine if you avoid JavaScript.
When you are looking for a clean and hassle-free transfer of information from the source to your end, you can also set other request headers. The set () method of the headers sets a new value of the existing header.
Real web browsers hosts many headers set, which the target website can check and block your scraper. So, the idea is that your scraper should seem to come from a real browser. Try to use the headers that your current web browser is using. You can use “Accept-Encoding”, “Accept”, “Upgrade-Insecure-Requests”, and “Accept-Language” as these may appead coming from a real browser.
Some of the examples of headers from Google Chrome that you may use are:
“Accept”: “text/html,application/xhtml+xml,application/xml;q=0.9,image/webp.
“Accept-Language”: “en-US,en;q=0.9,es;q=0.8”.
The Referrer request-header is another way you can use to scrape a website. This header sends the address of the previous web page before the request is sent to the web server.
Referrer- http://www.google.com/
It gives the appearance that a normal user is trying to fetch the information from the pool of the internet. If you want to portray the web scraper’s traffic more organically, it will be best if you specify a random website before beginning the scraping session.
Website owners keep changing the layout of the website for it to load faster and improve performance. Frequent changes in the website can hinder the scraping. When your scraper enters a new environment, it stops the scraping process.
To avoid settling in such an environment, on regular basis you should run a test on the website you want to scrape. Find out all the changes and program your crawler accordingly so that it does not stop working in a changing environment.
If you want to scrape happily, you can fetch some content from the Google cache. These pages will also give you scripts and resources from the original URLs. This is a method to download a URL you want to see but indirectly using
http://www.google.com/search?&q=cache%3Ahttp%3A//webscraping.com.
This way the source website will not be able to block you rather they will not even know that it is you.
If you constantly use the same crawling pattern on the target website, soon you will observe that you are blocked. To not make the crawler movement predictable, you must add random scrolls, movements, or clicks. You should develop a pattern that resonates with the way a normal user would do.
Use the proxy server to pretend that you are in a different country. A proxy server allows you to own an IP address from various locations. You can choose from the set of IP addresses to choose a specific location. The idea is to show that you are not a repeated user and that you do not have a common pattern. It will save you from being caught by the target website.
Calling it to match the trend now, make sure that you execute the JavaScript in your browser. If your scraper misses the JavaScript, it may not render websites properly. Hence, you will not get any information plus this is like leaving a trace that you are a bot.
Web Scraping with JavaScript involves basic steps to include sending the HTTP request, parsing the HTTP response and extracting the data, and saving the data in some database.
Use a proxy server that can protect you from being blacklisted. A proxy server is a third-party server that allows you to route your request through their servers. In the end, you use the IP address of these proxy servers.
Using a single IP can lead to the detection of your scraper. This is why you need a cluster of different IP addresses and then route them for your requests. Avoid using cheap or sharing proxy servers because they are prone to get blocked or blacklisted.
The residential proxy service helps to scrape 100% of big websites like Yelp, Aliexpress, Amazon, etc successfully. While the data center proxy can be used for small scraping projects.
Make sure you check the robots.txt file and respect the rules that are mentioned. Crawl only the pages that are allowed and immediately leave the place that objects.
You can try to parallelize the program but will have to be careful. The parallelizing refers to scraping the data and preprocessing of the data along with. It reduces the number of requests per second that you send to the page. When you follow the trend, you control the chances of being detected as a bot and getting blocked.
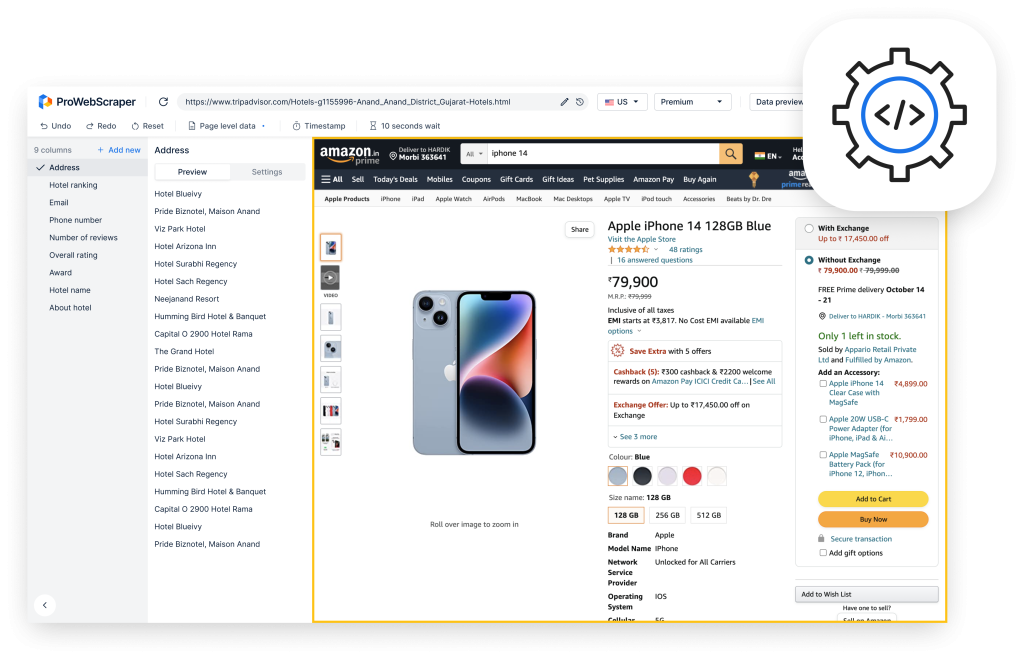
Hope these tips mentioned here help you when you are looking for ways on how to accomplish scraping without getting blocked. Scraping tools assist you to extract data without hassles and minimize the chances of getting blocked.
If you are looking for a web scraping bot, you can use a tool from ProWebScraper. This scraping tool avoids getting banned because it never gets blocked out of millions of IP addresses. The best part of the tool is that you do not require to learn any coding for it. The software tool is affordable and allows large-scale web scraping.
Book a demo with ProWebScraper and get 2000 pages of free scraping from us!