As an automated program or script, web crawler systematically crawls through web pages in order to work out the index of the data that it sets out to extract. In terms of the process, it is called web crawling or spidering.
You might wonder what a web crawling application or web crawler is and how it might work. Check out this video here to know more.
The tools that you use for the process are termed as web spiders, web data extraction software and website scraping tools.
The reason why web crawling applications matter so much today is because they can accelerate the growth of a business in many ways. In a data-driven world, these applications come quite handy as they collate information and content from diverse public websites and provide the same in a format that is manageable. With the help of these applications, you can keep an eye on crumbs of information scattered all over- the news, social media, images, articles, your competition etc.
In order to leverage these applications, it is needed to survey and understand the different aspects and features of the same. In this blog, we will take you through the different open source web crawling library and tools which can help you in crawling, scraping the web and parsing out the data.
We have put together a comprehensive summary of the best open source web crawling library and tools available in each language:

- Scalable: Handle large-scale scraping needs with ease.
- Robust QA: Hybrid QA process for accurate data extraction.
- Uninterrupted Scraping: residential proxies that never get blocked while scraping.
Open Source Web Crawler in Python:
1. Scrapy:
- Language : Python
- Github star : 28660
- Support

Description :
- Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages.
- It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
- Its built for extracting specific information from websites and allows you to focus on the data extraction using CSS selectors and choosing XPath expressions.
- If you are familiar with Python you’ll be up and running in just a couple of minutes.
- It runs on Linux, Mac OS, and Windows systems.
Features :
- Built-in support for extracting data from HTML/XML sources using extended CSS selectors and XPath expressions.
- Generating feed exports in multiple formats (JSON, CSV, XML).
- Built on Twisted
- Robust encoding support and auto-detection.
- Fast and powerful.
– Documentation : https://docs.scrapy.org/en/latest/
– Official site : https://scrapy.org/
2. Cola:
- Language : Python
- Github star : 1274
- Support
Description :
- Cola is a high-level distributed crawling framework, used to crawl pages and extract structured data from websites.
- It provides simple and fast yet flexible way to achieve your data acquisition objective.
- Users only need to write one piece of code which can run under both local and distributed mode.
Features :
- High-level distributed crawling framework
- Simple and fast
- Flexible
– Documentation : https://github.com/chineking/cola
– Official site : https://pypi.org/project/Cola/
3. Crawley:
- Language : Python
- Github star : 144
- Support
Description :
- Crawley is a pythonic Scraping / Crawling Framework intended to make easy the way you extract data from web pages into structured storages such as databases.
Features :
- High Speed WebCrawler built on Eventlet.
- Supports relational databases engines like Postgre, Mysql, Oracle, Sqlite.
- Supports NoSQL databases like Mongodb and Couchdb. New!
- Export your data into Json, XML or CSV formats. New!
- Command line tools.
- Extract data using your favourite tool. XPath or Pyquery (A Jquery-like library for python).
- Cookie Handlers.
– Documentation : https://pythonhosted.org/crawley/
– Official site : http://project.crawley-cloud.com/
4. MechanicalSoup:
- Language : Python
- Github star : 2803
- Support
Description :
- MechanicalSoup is a python library that is designed to simulate the behavior of a human using a web browser and built around the parsing library BeautifulSoup.
- If you need to scrape data from simple sites or if heavy scraping is not required, using MechanicalSoup is a simple and efficient method.
- MechanicalSoup automatically stores and sends cookies, follows redirects and can follow links and submit forms.
Features :
- Lightweight
- Cookie Handlers.
– Documentation : https://mechanicalsoup.readthedocs.io/en/stable/
– Official site : https://mechanicalsoup.readthedocs.io/
5. PySpider :
- Language : Python
- Github star : 11803
- Support
Description :
- PySpider is a Powerful Spider(Web Crawler) System in Python.
- It supports Javascript pages and has a distributed architecture.
- PySpider can store the data on a backend of your choosing database such as MySQL, MongoDB, Redis, SQLite, Elasticsearch, Etc.
- You can use RabbitMQ, Beanstalk, and Redis as message queues.
Features :
- Powerful WebUI with script editor, task monitor, project manager and result viewer
- Supports heavy AJAX websites.
- Facilitates more comfortable and faster scraping
– Documentation : http://docs.pyspider.org/
– Official site : https://github.com/binux/pyspider
6. Portia :
- Language : Python
- Github star : 6250
- Support

Description :
- Portia is a visual scraping tool created by Scrapinghub that does not require any programming knowledge.
- If you are not a developer, its best to go straight with Portia for your web scraping needs.
- You can try Portia for free without needing to install anything, all you need to do is sign up for an account at Scrapinghub and you can use their hosted version.
- Making a crawler in Portia and extracting web contents is very simple if you do not have programming skills.
- You won’t need to install anything as Portia runs on the web page.
- With Portia, you can use the basic point-and-click tools to annotate the data you wish to extract, and based on these annotations Portia will understand how to scrape data from similar pages.
- Once the pages are detected Portia will create a sample of the structure you have created.
Features :
- Actions such as click, scroll, wait are all simulated by recording and replaying user actions on a page.
- Portia is great to crawl Ajax powered based websites (when subscribed to Splash) and should work fine with heavy Javascript frameworks like Backbone, Angular, and Ember.
– Documentation : https://portia.readthedocs.io/en/latest/index.html
– Official site : https://github.com/scrapinghub/portia
7. Beautifulsoup :
- Language : Python
- Support

Description :
- Beautiful Soup is a Python library designed for quick turnaround projects like web scraping
- It sits atop an HTML or XML parser, providing Pythonic idioms for iterating, searching, and modifying the parse tree.It commonly saves programmers hours or days of work.
Features :
- Beautiful Soup automatically converts incoming documents to Unicode and outgoing documents to UTF-8.
- Beautiful Soup sits on top of popular Python parsers like lxml and html5lib, allowing you to try out different parsing strategies or trade speed for flexibility.
– Documentation : https://www.crummy.com/software/BeautifulSoup/bs4/doc/
– Official site : https://www.crummy.com/software/BeautifulSoup/
8. Spidy Web Crawler :
- Language : Python
- Github star : 152
- Support

Description :
- Spidy is a Web Crawler which is easy to use and is run from the command line. You have to give it a URL link of the webpage and it starts crawling away! A very simple and effective way of fetching stuff off of the web.
- It uses Python requests to query the webpages, and lxml to extract all links from the page.Pretty simple!
Features :
- Error Handling
- Cross-Platform compatibility
- Frequent Timestamp Logging
- Portability
- User-Friendly Logs
- Webpage saving
- File Zipping
– Documentation : https://github.com/rivermont/spidy
– Official site : http://project.crawley-cloud.com/
9. Grab :
- Language : Python
- Github star : 1627
- Support
Description :
- Grab is a python framework for building web scrapers.
- With Grab you can build web scrapers of various complexity, from simple 5-line scripts to complex asynchronous website crawlers processing millions of web pages.
- Grab provides an API for performing network requests and for handling the received content e.g. interacting with DOM tree of the HTML document.
Features :
- HTTP and SOCKS proxy with/without authorization
- Automatic charset detection
- Powerful API to extract data from DOM tree of HTML documents with XPATH queries
- Automatic cookies (session) support
– Documentation : https://grablib.org/en/latest/
– Official site : https://github.com/lorien/grab
Open Source Web Crawler Java :
10. Apache Nutch :
- Language : Java
- Github star : 1743
- Support

Description :
- Apache Nutch is a highly extensible and scalable open source web crawler software project.
- When it comes to best open source web crawlers, Apache Nutch definitely has a top place in the list.
- Apache Nutch is popular as a highly extensible and scalable open source code web data extraction software project great for data mining.
- Nutch can run on a single machine but a lot of its strength is coming from running in a Hadoop cluster.
- Many data analysts and scientists, application developers, and web text mining engineers all over the world use Apache Nutch.
- Apache Nutch is a cross-platform solution written in Java.
Features :
- Fetching and parsing are done separately by default
- Supports a wide variety of document formats: Plain Text, HTML/XHTML+XML, XML, PDF, ZIP and many others
- Uses XPath and namespaces to do the mapping
- Distributed file system (via Hadoop)
- Link-graph database
- NTLM authentication
– Documentation : https://wiki.apache.org/nutch/
– Official site : http://nutch.apache.org/
11. Heritrix :
- Language : Java
- Github star :1236
- Support
Description :
- Heritrix is one of the most popular free and open-source web crawlers in Java. Actually, it is an extensible, web-scale, archival-quality web scraping project.
- Heritrix is a very scalable and fast solution. You can crawl/archive a set of websites in no time. In addition, it is designed to respect the robots.txt exclusion directives and META robots tags.
- Runs on Linux/Unix like and Windows.
Features :
- HTTP authentication
- NTLM Authentication
- XSL Transformation for link extraction
- Search engine independence
- Mature and stable platform
- Highly configurable
- Runs from any machine
– Documentation : https://github.com/internetarchive/heritrix3/wiki/Heritrix%203.0%20and%203.1%20User%20Guide
– Official site : https://github.com/internetarchive/heritrix3b
12. ACHE Crawler :
- Language : Java
- Github star : 154
- Support

Description :
- ACHE is a focused web crawler.
- It collects web pages that satisfy some specific criteria, e.g., pages that belong to a given domain or that contain a user-specified pattern.
- ACHE differs from generic crawlers in sense that it uses page classifiers to distinguish between relevant and irrelevant pages in a given domain.
- A page classifier can be from a simple regular expression (that matches every page that contains a specific word, for example), to a machine-learning based classification model. ACHE can also automatically learn how to prioritize links in order to efficiently locate relevant content while avoiding the retrieval of irrelevant content.
Features :
- Regular crawling of a fixed list of websites
- Discovery and crawling of new relevant websites through automatic link prioritization
- Configuration of different types of pages classifiers (machine-learning, regex, etc)
- Continuous re-crawling of sitemaps to discover new pages
- Indexing of crawled pages using Elasticsearch
- Web interface for searching crawled pages in real-time
- REST API and web-based user interface for crawler monitoring
- Crawling of hidden services using TOR proxies
– Documentation : http://ache.readthedocs.io/en/latest/
– Official site : https://github.com/ViDA-NYU/ache
13. Crawler4j :
- Language : Java
- Github star : 3039
- Support
Description :
- crawler4j is an open source web crawler for Java which provides a simple interface for crawling the Web.
- Using it, you can setup a multi-threaded web crawler in few minutes.
– Documentation : https://github.com/yasserg/crawler4j
– Official site : https://github.com/yasserg/crawler4j
14. Gecco :
- Language : Java
- Github star : 1245
- Support
Description :
- Gecco is a easy to use lightweight web crawler developed with java language.Gecco integriert jsoup, httpclient, fastjson, spring, htmlunit, redission ausgezeichneten framework,Let you only need to configure a number of jQuery style selector can be very quick to write a crawler.
- Gecco framework has excellent scalability, the framework based on the principle of open and close design, to modify the closure, the expansion of open.
Features :
- Easy to use, use jQuery style selector to extract elements
- Support for asynchronous Ajax requests in the page
- Support page JavaScript variable extraction
- Using Redis to realize distributed crawling,reference gecco-redis
- Support the development of business logic with Spring,reference gecco-spring
- Support htmlunit extension,reference gecco-htmlunit
- Support extension mechanism
- Support download UserAgent random selection
- Support the download proxy server randomly selected
– Documentation : https://github.com/xtuhcy/gecco
– Official site : https://github.com/xtuhcy/gecco
15. BUbiNG :
- Language : Java
- Github star :24
- Support
Description :
- BUbiNG will surprise you. It is a next-generation open source web crawler. BUbiNG is a Java fully distributed crawler (no central coordination). It is able to crawl several thousands pages per second. Collect really big datasets.
- BUbiNG distribution is based on modern high-speed protocols so to achieve very high throughput.
- BUbiNG provides massive crawling for the masses. It is completely configurable, extensible with little efforts and integrated with spam detection.
Features :
- High parallelism
- Fully distributed
- Uses JAI4J, a thin layer over JGroups that handles job assignment.
- Detects (presently) near-duplicates using a fingerprint of a stripped page
- Fast
- Massive crawling.
– Documentation : http://law.di.unimi.it/software/bubing-docs/index.html
– Official site : http://law.di.unimi.it/software.php#bubing
16. Narconex :
- Language : Java
- Support

Description :
- A great tool for those who are searching open source web crawlers for enterprise needs.
- Norconex allows you to crawl any web content. You can run this full-featured collector on its own, or embed it in your own application.
- Works on any operating system. Can crawl millions on a single server of average capacity. In addition, it has many content and metadata manipulation options. Also, it can extract page “featured” image.
Features :
- Multi-threaded
- Supports different hit interval according to different schedules
- Extract text out of many file formats (HTML, PDF, Word, etc.)
- Extract metadata associated with documents
- Supports pages rendered with JavaScript
- Language detection
- Translation support
- Configurable crawling speed
- Detects modified and deleted documents
- Supports external commands to parse or manipulate documents
– Documentation : http://www.norconex.com/collectors/collector-http/getting-started
– Official site : http://www.norconex.com/collectors/collector-http/
17. WebSPHINX :
- Language : Java
- No support Available

Description :
- WebSphinix is a great easy to use personal and customizable web crawler. It is designed for advanced web users and Java programmers allowing them to crawl over a small part of the web automatically.
- This web data extraction solution also is a comprehensive Java class library and interactive development software environment. WebSphinix includes two parts: the Crawler Workbench and the WebSPHINX class library.
- The Crawler Workbench is a good graphical user interface that allows you to configure and control a customizable web crawler. The library provides support for writing web crawlers in Java.
- WebSphinix runs on Windows, Linux, Mac, and Android IOS.
Features :
- Visualize a collection of web pages as a graph
- Concatenate pages together for viewing or printing them as a single document
- Extract all text matching a certain pattern.
- Tolerant HTML parsing
- Support for the robot exclusion standard
- Common HTML transformations
- Multithreaded Web page retrieval
– Documentation : https://www.cs.cmu.edu/~rcm/websphinx/doc/index.html
– Official site : https://www.cs.cmu.edu/~rcm/websphinx/#about
18. Spiderman :
- Language : Java
- Github star : 2400
- Support
Description :
- Spiderman is a Java open source web data extraction tool. It collects specific web pages and extracts useful data from those pages.
- Spiderman mainly uses techniques such as XPath and regular expressions to extract real data.
Features :
- higher performance
- collection state persistence
- Distributed
- support JS script
– Documentation : https://gitee.com/l-weiwei/spiderman
– Official site : https://gitee.com/l-weiwei/spiderman
19. WebCollector :
- Language : Java
- Github star : 1986
- Support
Description :
- WebCollector is an open source web crawler framework based on Java.
- It provides some simple interfaces for crawling the Web,you can setup a multi-threaded web crawler in less than 5 minutes.
Features :
- Fast
– Documentation : https://github.com/CrawlScript/WebCollector
– Official site : https://github.com/CrawlScript/WebCollector
20. Webmagic :
- Language : Java
- Github star : 6891
- Support

Description :
- A scalable crawler framework.
- It covers the whole lifecycle of crawler: downloading, url management, content extraction and persistent.
- It can simplify the development of a specific crawler.
Features :
- Simple core with high flexibility.
- Simple API for html extracting.
- Annotation with POJO to customize a crawler, no configuration.
- Multi-thread and Distribution support.
- Easy to be integrated.
– Documentation : http://webmagic.io/docs/en/
– Official site : https://github.com/code4craft/webmagic
21. StormCrawler :
- Language : Java
- Github star : 437
- Support

Description :
- StormCrawler is an open source SDK for building distributed web crawlers based on Apache Storm.
- StormCrawler is a library and collection of resources that developers can leverage to build their own crawlers.
- StormCrawler is perfectly suited to use cases where the URL to fetch and parse come as streams but is also an appropriate solution for large scale recursive crawls, particularly where low latency is required.
Features :
- scalable
- resilient
- low latency
- easy to extend
- polite yet efficient
– Documentation : http://stormcrawler.net/docs/api/
– Official site : http://stormcrawler.net/
Open Source Web Crawler JavaScript :
22. Node-Crawler :
- Language : Javascript
- Github star : 3999
- Support

Description :
- Nodecrawler is a popular web crawler for NodeJS, making it a very fast crawling solution.
- If you prefer coding in JavaScript, or you are dealing with mostly a Javascript project, Nodecrawler will be the most suitable web crawler to use. Its installation is pretty simple too.
- JSDOM and Cheerio (used for HTML parsing) use it for server-side rendering, with JSDOM being more robust.
Features :
- server-side DOM & automatic jQuery insertion with Cheerio (default) or JSDOM
- Configurable pool size and retries
- Control rate limit
- Priority queue of requests
- forceUTF8 mode to let crawler deal for you with charset detection and conversion
- Compatible with 4.x or newer version
– Documentation : https://github.com/bda-research/node-crawler
– Official site : http://nodecrawler.org/
23. Simplecrawler :
- Language : Javascript
- Github star :1764
- Support
Description :
- simplecrawler is designed to provide a basic, flexible and robust API for crawling websites.
- It was written to archive, analyse, and search some very large websites and has happily chewed through hundreds of thousands of pages and written tens of gigabytes to disk without issue.
Features :
- Provides some simple logic for auto-detecting linked resources – which you can replace or augment
- Automatically respects any robots.txt rules
- Has a flexible queue system which can be frozen to disk and defrosted
– Documentation : https://github.com/simplecrawler/simplecrawler
– Official site : https://www.npmjs.com/package/simplecrawler
24. Js-crawler :
- Language : Javascript
- Github star : 167
- Support
Description :
- Web crawler for Node.JS, both HTTP and HTTPS are supported.
– Documentation : https://github.com/antivanov/js-crawler
– Official site : https://github.com/antivanov/js-crawler
25. Webster :
- Language : Javascript
- Github star : 201
- Support
Description :
- Webster is a reliable web crawling and scraping framework written with Node.js, used to crawl websites and extract structured data from their pages.
- Which is different from other crawling framework is that Webster can scrape the content which rendered by browser client side javascript and ajax request.
– Documentation : http://webster.zhuyingda.com/
– Official site : https://github.com/zhuyingda/webster
26. Node-osmosis :
- Language : Javascript
- Github star : 3630
- Support
Description :
- HTML/XML parser and web scraper for NodeJS.
Features :
- Uses native libxml C bindings
- Clean promise-like interface
- Supports CSS 3.0 and XPath 1.0 selector hybrids
- Sizzle selectors, Slick selectors, and more
- No large dependencies like jQuery, cheerio, or jsdom
- Compose deep and complex data structures
- HTML parser features
- Fast parsing
- Very fast searching
- Small memory footprint
- HTML DOM features
- Load and search ajax content
- DOM interaction and events
- Execute embedded and remote scripts
- Execute code in the DOM
- HTTP request features
- Logs urls, redirects, and errors
- Cookie jar and custom cookies/headers/user agent
- Login/form submission, session cookies, and basic auth
- Single proxy or multiple proxies and handles proxy failure
- Retries and redirect limits
– Documentation : https://rchipka.github.io/node-osmosis/global.html
– Official site : https://www.npmjs.com/package/osmosis
27. Supercrawler :
- Language : Javascript
- Github star : 4341
- Support
Description :
- Supercrawler is a Node.js web crawler. It is designed to be highly configurable and easy to use.
- When Supercrawler successfully crawls a page (which could be an image, a text document or any other file), it will fire your custom content-type handlers. Define your own custom handlers to parse pages, save data and do anything else you need.
Features :
- Link Detection : Supercrawler will parse crawled HTML documents, identify links and add them to the queue.
- Robots Parsing : Supercrawler will request robots.txt and check the rules before crawling. It will also identify any sitemaps.
- Sitemaps Parsing : Supercrawler will read links from XML sitemap files, and add links to the queue.
- Concurrency Limiting : Supercrawler limits the number of requests sent out at any one time.
- Rate limiting : Supercrawler will add a delay between requests to avoid bombarding servers.
- Exponential Backoff Retry : Supercrawler will retry failed requests after 1 hour, then 2 hours, then 4 hours, etc. To use this feature, you must use the database-backed or Redis-backed crawl queue.
- Hostname Balancing : Supercrawler will fairly split requests between different hostnames. To use this feature, you must use the Redis-backed crawl queue.
– Documentation : https://github.com/brendonboshell/supercrawler
– Official site : https://github.com/brendonboshell/supercrawler
28. Web scraper chrome extension :
- Language : Javascript
- Github star : 775
- Support
Description :
- Web Scraper is a chrome browser extension built for data extraction from web pages.
- Using this extension you can create a plan (sitemap) how a web site should be traversed and what should be extracted.
- Using these sitemaps the Web Scraper will navigate the site accordingly and extract all data.
- Scraped data later can be exported as CSV.
Features :
- Scrape multiple pages
- Sitemaps and scraped data are stored in browsers local storage or in CouchDB
- Multiple data selection types
- Extract data from dynamic pages (JavaScript+AJAX)
- Browse scraped data
- Export scraped data as CSV
- Import, Export sitemaps
- Depends only on Chrome browser
– Documentation : https://www.webscraper.io/documentation
– Official site : https://www.webscraper.io
29. Headless chrome crawler :
- Language : Javascript
- Github star : 3256
- Support

Description :
- Crawlers based on simple requests to HTML files are generally fast.
- However, it sometimes ends up capturing empty bodies, especially when the websites are built on such modern frontend frameworks as AngularJS, React and Vue.js.
Features :
- Distributed crawling
- Configure concurrency, delay and retry
- Support both depth-first search and breadth-first search algorithm
- Pluggable cache storages such as Redis
- Support CSV and JSON Lines for exporting results
- Pause at the max request and resume at any time
- Insert jQuery automatically for scraping
- Save screenshots for the crawling evidence
- Emulate devices and user agents
- Priority queue for crawling efficiency
– Documentation : https://github.com/yujiosaka/headless-chrome-crawler/blob/master/docs/API.md
– Official site : https://github.com/yujiosaka/headless-chrome-crawler
30. X-ray :
- Language : Javascript
- Github star : 4464
- Support

Features :
- Flexible schema: Supports strings, arrays, arrays of objects, and nested object structures. The schema is not tied to the structure of the page you’re scraping, allowing you to pull the data in the structure of your choosing.
- Composable: The API is entirely composable, giving you great flexibility in how you scrape each page.
- Pagination support: Paginate through websites, scraping each page. X-ray also supports a request delay and a pagination limit. Scraped pages can be streamed to a file, so if there’s an error on one page, you won’t lose what you’ve already scraped.
- Crawler support: Start on one page and move to the next easily. The flow is predictable, following a breadth-first crawl through each of the pages.
- Responsible: X-ray has support for concurrency, throttles, delays, timeouts and limits to help you scrape any page responsibly.
- Pluggable drivers: Swap in different scrapers depending on your needs.
– Documentation : https://github.com/matthewmueller/x-ray
– Official site : https://www.npmjs.com/package/x-ray-scraper
Open Source Web Crawler in C :
31. Httrack :
- Language : C
- Github star : 747
- Support

Description :
- HTTrack is a free (GPL, libre/free software) and easy-to-use offline browser utility.
- It allows you to download a World Wide Web site from the Internet to a local directory, building recursively all directories, getting HTML, images, and other files from the server to your computer.
- HTTrack arranges the original site’s relative link-structure. Simply open a page of the “mirrored” website in your browser, and you can browse the site from link to link, as if you were viewing it online.
- HTTrack can also update an existing mirrored site, and resume interrupted downloads.
- HTTrack is fully configurable, and has an integrated help system.
Features :
- Multilingual Windows and Linux/Unix interface
- Mirror one site, or more than one site together
- Filter by file type, link location, structure depth, file size, site size, accepted or refused sites or filename
- Proxy support to maximize speed, with optional authentication
– Documentation : http://www.httrack.com/html/index.html
– Official site : http://www.httrack.com/
32. GNU Wget :
- Language : C
- Github star : 22
- Support

Description :
- GNU Wget is a free software package for retrieving files using HTTP, HTTPS, FTP and FTPS the most widely-used Internet protocols.
- It is a non-interactive command line tool, so it may easily be called from scripts, cron jobs, terminals without X-Windows support, etc.
Features :
- Can resume aborted downloads, using REST and RANGE
- NLS-based message files for many different languages
- Runs on most UNIX-like operating systems as well as Microsoft Windows
- Supports HTTP proxies
- Supports HTTP cookies
– Documentation : https://www.gnu.org/software/wget/manual/
– Official site : https://www.gnu.org/software/wget/
Open Source Web Crawler in C++ :
33. Open-source-search-engine :
- Language : C++
- Github star : 912
- Support
Description :
- An open source web and enterprise search engine and spider/crawler
- Gigablast is one of a handful of search engines in the United States that maintains its own searchable index of over a billion pages.
Features :
- Large scale
- High performance
- Real time information retrieval technology
– Documentation : http://www.gigablast.com/api.html
– Official site : http://www.gigablast.com/
Open Source Web Crawler in C# :
34. Arachnode.net :
- Language : C#
- Github star : 9
- Support
Description :
- Arachnode.net is for those who are looking for open source web crawlers in is a C#. Arachnode.net is a class library which downloads content from the internet, indexes this content and provides methods to customize the process.
- You can use the tool for personal content aggregation or you can use the tool for extracting, collecting and parse downloaded content into multiple forms. Discovered content is indexed and stored in Lucene.NET indexes.
- Arachnode.net is a good software solution for text mining purposes as well as for learning advanced crawling techniques.
Features :
- Configurable rules and actions
- Lucene.NET Integration
- SQL Server and full-text indexing
- .DOC/.PDF/.PPT/.XLS Indexing
- HTML to XML and XHTML
- Full JavaScript/AJAX Functionality
- Multi-threading and throttling
- Respectful crawling
- Analysis services
– Documentation : https://documentation.arachnode.net/index.html
– Official site : http://arachnode.net/
35. Abot :
- Language : C#
- Github star : 1392
- Support
Description :
- Abot is an open source C# web crawler built for speed and flexibility.
- It takes care of the low level plumbing (multithreading, http requests, scheduling, link parsing, etc..).
- You just register for events to process the page data.
- You can also plugin your own implementations of core interfaces to take complete control over the crawl process.
Features :
- It’s fast!!
- Easily customizable (Pluggable architecture allows you to decide what gets crawled and how)
- Heavily unit tested (High code coverage)
- Very lightweight (not over engineered)
- No out of process dependencies (database, installed services, etc…)
– Documentation : https://github.com/sjdirect/abot
– Official site : https://github.com/sjdirect/abot
36. Hawk :
- Language : C#
- Github star : 1875
- Support
Description :
- HAWK requires no programming, visible graphical data acquisition and cleaning tools, open source according to the GPL protocol.
Features :
- Intelligent analysis of web content without programming
- WYSIWYG, visual drag and drop, fast data processing such as conversion and filtering
- Can import and export from various databases and files
- Tasks can be saved and reused
- The most suitable area is reptile and data cleaning, but its power is far beyond this.
– Documentation : https://github.com/ferventdesert/Hawk
– Official site : https://ferventdesert.github.io/Hawk/
37. SkyScraper :
- Language : C#
- Github star : 39
- Support
Description :
- An asynchronous web scraper / web crawler using async / await and Reactive Extensions
– Documentation : https://github.com/JonCanning/SkyScraper
– Official site : https://github.com/JonCanning/SkyScraper
Open Source Web Crawler in .NET :
38. DotnetSpider :
- Language : .NET
- Github star : 1382
- Support
Description :
- DotnetSpider, a .NET Standard web crawling library similar to WebMagic and Scrapy. It is a lightweight ,efficient and fast high-level web crawling & scraping framework for .NET
– Documentation : https://github.com/dotnetcore/DotnetSpider/wiki
– Official site : https://github.com/dotnetcore/DotnetSpider
Open Source Web Crawler in PHP :
39. Goutte :
- Language : PHP
- Github star : 6574
- Support
Description :
- Goutte is a screen scraping and web crawling library for PHP.
- Goutte provides a nice API to crawl websites and extract data from the HTML/XML responses.
– Documentation : https://goutte.readthedocs.io/en/latest/
– Official site : https://github.com/FriendsOfPHP/Goutte
40. Dom-crawler :
- Language : PHP
- Github star : 1340
- Support
Description :
- The DomCrawler component eases DOM navigation for HTML and XML documents
– Documentation : https://symfony.com/doc/current/components/dom_crawler.html
– Official site : https://github.com/symfony/dom-crawler
41. Pspider :
- Language : PHP
- Github star : 249
- Support
Description :
- This is a parallel crawling (crawler) framework recently developed using pure PHP code, based on the hightman\httpclient component.
– Documentation : https://github.com/hightman/pspider
– Official site : https://github.com/hightman/pspider
42. Php-spider :
- Language : PHP
- Github star : 1023
- Support
Description :
- A configurable and extensible PHP web spider
Features :
- supports crawl depth limiting, queue size limiting and max downloads limiting
- supports adding custom URI discovery logic, based on XPath, CSS selectors, or plain old PHP
- comes with a useful set of URI filters, such as Domain limiting
- collects statistics about the crawl for reporting
– Documentation : https://github.com/mvdbos/php-spider
– Official site : https://github.com/mvdbos/php-spider
43. Spatie / Crawler :
- Language : PHP
- Github star : 740
- Support
Description :
- This package provides a class to crawl links on a website.
- Under the hood Guzzle promises are used to crawl multiple urls concurrently.
- Because the crawler can execute JavaScript, it can crawl JavaScript rendered sites. Under the hood Chrome and Puppeteer are used to power this feature.
– Documentation : https://github.com/spatie/crawler
– Official site : https://github.com/spatie/crawler
Open Source Web Crawler in Ruby :
44. Mechanize :
- Language : Ruby
- Github star : 3728
- Support
Description :
- The Mechanize library is used for automating interaction with websites.
- Mechanize automatically stores and sends cookies, follows redirects, and can follow links and submit forms. Form fields can be populated and submitted.
- Mechanize also keeps track of the sites that you have visited as a history.
– Documentation : http://docs.seattlerb.org/mechanize/
– Official site : https://github.com/sparklemotion/mechanize
Open Source Web Crawler in GO :
45. Colly :
- Language : Go
- Github star : 5439
- Support

Description :
- Lightning Fast and Elegant Scraping Framework for Gophers
- Colly provides a clean interface to write any kind of crawler/scraper/spider.
- With Colly you can easily extract structured data from websites, which can be used for a wide range of applications, like data mining, data processing or archiving.
Features :
- Clean API
- Fast (>1k request/sec on a single core)
- Manages request delays and maximum concurrency per domain
- Automatic cookie and session handling
- Sync/async/parallel scraping
- Caching
- Automatic encoding of non-unicode responses
- Robots.txt support
- Distributed scraping
- Configuration via environment variables
- Extensions
– Documentation : http://go-colly.org/docs/
– Official site : http://go-colly.org/
46. Gopa :
- Language : Go
- Github star : 169
- Support
Features :
- Light weight, low footprint, memory requirement should < 100MB
- Easy to deploy, no runtime or dependency required
- Easy to use, no programming or scripts ability needed, out of box features
– Documentation : https://github.com/infinitbyte/gopa
– Official site : https://github.com/infinitbyte/gopa
47. Pholcus :
- Language : Go
- Github star : 4341
- Support

Description :
- Pholcus is a purely high-concurrency, heavyweight crawler software written in pure Go language.
- It is targeted at Internet data collection and provides a feature that only requires attention to rule customization for those with a basic Go or JS programming foundation.
- The rules are simple and flexible, batch tasks are concurrent, and output methods are rich (mysql/mongodb/kafka/csv/excel, etc.).
- There is a large amount of Demo sharing; in addition, it supports two horizontal and vertical crawl modes, supporting a series of advanced functions such as simulated login and task pause and cancel.
Features :
- A powerful reptile tool.
- It supports three operating modes: stand-alone, server, and client.
- It has three operation interfaces: Web, GUI, and command line.
– Documentation : https://pholcus.gitbooks.io/docs/
– Official site : https://github.com/henrylee2cn/pholcus
Open Source Web Crawler in R :
48. Rvest :
- Language : R
- Github star : 969
- Support
Description :
- rvest helps you scrape information from web pages. It is designed to work with magrittr to make it easy to express common web scraping tasks, inspired by libraries like beautiful soup.
– Documentation : https://cran.r-project.org/web/packages/rvest/rvest.pdf
– Official site : https://github.com/hadley/rvest
Scala :
49. Sparkler :
- Language : Scala
- Github star : 198
- Support
Description :
- A web crawler is a bot program that fetches resources from the web for the sake of building applications like search engines, knowledge bases, etc.
- Sparkler (contraction of Spark-Crawler) is a new web crawler that makes use of recent advancements in distributed computing and information retrieval domains by conglomerating various Apache projects like Spark, Kafka, Lucene/Solr, Tika, and pf4j.
Features :
- Provides Higher performance and fault tolerance
- Supports complex and near real-time analytics
- Streams out the content in real-time
- Extensible plugin framework
- Universal Parser
– Documentation : http://irds.usc.edu/sparkler/dev/development-environment-setup.html#contributing-source
– Official site : http://irds.usc.edu/sparkler/
Open Source Web Crawler in Perl :
50. Web-scraper :
- Language : Perl
- Github star : 91
- Support
Description :
- Web Scraper is Web Scraping Toolkit using HTML and CSS Selectors or XPath expressions
– Documentation : https://github.com/miyagawa/web-scraper
– Official site : https://github.com/miyagawa/web-scraper
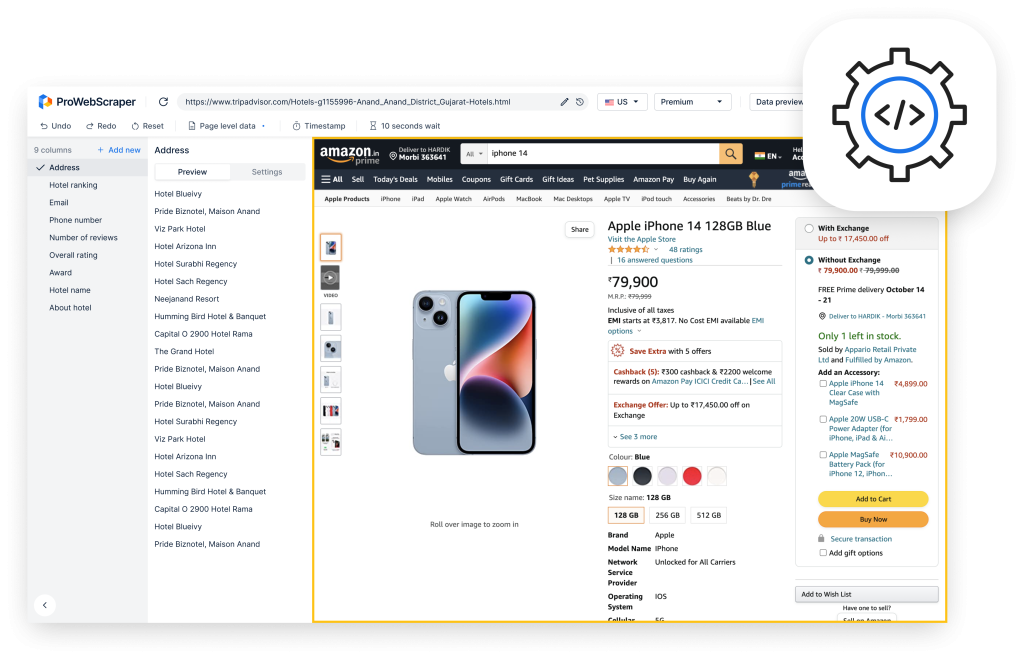
Conclusion
The universe of open source web crawling applications is vast and mind-boggling.
Each one is packed with its unique features and what it can accomplish for you.
Based on your need and technical know-how, you can capitalize on these tools. You may or may not obsess with any one tool. In fact, you may use different tools for different tasks you may come across.
It actually depends on the end user. However, it is paramount that you understand the unique strengths of each tool and harness its strengths to leverage your business or any other task you have undertaken.
Feel free to write to us regarding any queries you might have regarding any of these tools.
Do share your valuable feedback and comments regarding the blog!